Immaginiamo di voler creare in C# una classe generica che possa gestire dei tipi aperti, un po’ come succede per le liste. Per esercizio vogliamo creare una classe chiamata Materie che accetti diverse classi come tipo di materia gestito, per esempio una classe Matematica. L’oggetto che vogliamo creare sarà di questo tipo:
C#
1
Materie<Matematica>m=newMaterie<Matematica>();
A questo punto vogliamo avere un metodo per aggiungere dei voti per gli studenti della data materia, nel modo seguente:
1
m.addVoto(newMatematica("Mario",10));
E infine vogliamo poter estrarre, dal nostro oggetto m, una media dei voti, passandogli una funzione che si occuperà di definire il meccanismo di estrazione del voto dall’oggetto generico sul tipo aperto.
Faccio notare che il metodo getMediaVoti accetta come argomento un metodo generico che prenda che abbia come argomento il tipo aperto T e come restituzione un double (supponiamo che volendo calcolare dei voti essi dovranno essere comunque ricondotti a double).
Uniamo il tutto nel modo seguente:
C#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
classProgram
{
staticvoidMain(string[]args)
{
Materie<Matematica>m=newMaterie<Matematica>();
m.addVoto(newMatematica("Mario",10));
m.addVoto(newMatematica("Luigi",8));
m.addVoto(newMatematica("Luisa",9));
doublemedia=m.getMediaVoti(calcolaMedia);
Console.WriteLine("media {0}",media);
Console.ReadLine();
}
staticdoublecalcolaMedia(Matematicam)
{
returnm.voto;
}
}
In questo caso l’oggetto m si comporta in modo analogo ad una lista, permettendo l’aggiunta di n elementi del tipo T, nel nostro caso Matematica. Dal momento che noi non conosciamo i specifici parametri e metodi di T chiediamo, per calcolare la media, che ci venga passata una funzione a cui sarà delegata l’estrazione dei voti come double dall’oggetto aperto di tipo T, tale metodo è calcolaMedia che accetta come argomento un oggetto di tipo Matematica.
In memoria di Stephen Hawking propongo un modesto esercizio in Python per calcolare il tempo di evaporazione di un buco nero, secondo la radiazione di Hawking.
In questo caso utilizzeremo le librerie scipy e numpy di Python.
Il mio esempio sarà fatto sotto Windows. Anzitutto installiamo quindi le librerie necessarie utilizzando pip, nella PowerShell digitiamo:
1
python-mpip install--user numpy scipy matplotlib ipython jupyter pandas sympy nose
Una volta fatto avviamo un nuovo progetto in python e andiamo anzitutto a calcolare la suddetta formula. L’equazione di evaporazione di un buco nero, che si trovasse in una condizione ideale (ovvero nessuna aggiunta di energia, quindi ipoteticamente in un universo completamente vuoto e senza radiazione di fondo) è la seguente:
Faccio notare che da scipy importiamo le costanti fisiche e matematiche che possiamo utilizzare secondo la seguente tabella.
M0 è l’ipotetica massa iniziale di un buco nero di massa solare, nello specifico di .
Il risultato dovrebbe essere:
1
6.617525584671073e+74
Il risultato è in secondi, possiamo convertirlo in miliardi di anni digitando:
Python
1
print(Tev/(3600*24*365*10**9))
Il risultato è qualcosa come miliardi di anni, molto più dell’attuale vita dell’universo stimata attorno ai 13 miliardi di anni.
Adesso proviamo ad inserire l’equazione in un grafico, dove vogliamo confrontare vari tipi di buco nero in base alla massa ed il tempo di evaporazione.
Per farlo anzitutto convertiamo la nostra precedente equazione in una funzione digitando:
Ricordiamoci che il risultato della funzione è in secondi. A questo punto prepariamo i valori del nostro asse x, che saranno le masse di diversi buchi neri. Prendiamo 100 valori tra 0 e 1030.
Python
1
X=np.linspace(0,10**30,100,endpoint=True)
Sull’asse Y calcoliamo i corrispondenti valori:
Python
1
Y=HawkingTev(X)
Adesso impacchettiamo tutto in un grafico generato con matplotlib.
Oggi propongo un piccolo esercizio in C# per chiunque volesse avvicinarsi a questo fantastico linguaggio di programmazione.
Obiettivo: realizzare un programma elementare da console che permetta di inserire degli atleti, con nomi e punteggi, visualizzarli a monitor, rimuoverli e stampare la media dei loro punteggi.
Per programmare con C# è sufficiente disporre di Visual Studio 2017. (la Community edition sarà più che sufficiente, basterà scegliere C# tra i pacchetti da installare)
Una volta installato avviamo un nuovo progetto andando su File ⇒ Nuovo ⇒ Progetto…
A questo punto comparirà una finestra che ci permetterà di scegliere che tipo di progetto vogliamo realizzare. Nel nostro caso applicazione per Console.
In fondo diamo un nome a piacere al nostro progetto, io lo chiamerà EsempioAtleti, e prendiamo nota della posizione dove verrà salvato (tipicamente nella cartella che abbiamo scelto, in fase di installazione, come cartella predefinita per i progetti).
Se abbiamo fatto tutto correttamente dovremmo ritrovarci con aperto il file Program.cs con dentro un contenuto simile a questo:
C#
1
2
3
4
5
6
7
8
9
10
11
12
namespaceEsempioAtleti
{
classProgram
{
staticvoidMain(string[]args)
{
}
}
}
Il metodo Main è quello che verrà eseguito automaticamente all’avvio dell’intero programma. Per fare una primissima prova e prendere leggermente confidenza con il programma possiamo digitare quanto segue:
C#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
namespaceEsempioAtleti
{
classProgram
{
staticvoidMain(string[]args)
{
Console.WriteLine("Ciao, Mondo!");
Console.ReadLine();
}
}
}
Avviamo il programma premendo F5 (oppure il tasto avvia con la freccia verde). Quello che vedremo sarà un prompt dei comandi con scritto “Ciao, Mondo!” ed il cursore in attesa di input. Se premiamo invio il prompt si chiuderà. Questo lo abbiamo ottenuto con la riga di codice Console.ReadLine(), senza la quale il programma terminerebbe immediatamente. In questo modo invece si mette in attesa di un nostro input, ricevuto il quale chiude tutto quanto.
Adesso cominciamo a creare un paio di classi, necessarie al nostro progetto. Per aggiungere una nuova classe è sufficiente cliccare col destro sul progetto nella finestra di esplorazione, selezionare Aggiungi ⇒ Classe.
Creeremo due classi, chiamate rispettivamente Atleti ed Atleta. La classe Atleti gestirà un gruppo di oggetti singoli di tipo Atleta. Vediamo anzitutto come sarà composta la classe Atleta:
C#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
usingSystem;
usingSystem.Collections.Generic;
usingSystem.Linq;
usingSystem.Text;
usingSystem.Threading.Tasks;
namespaceEsempioAtleti
{
classAtleta
{
privateStringnome;
privateInt32 punteggio;
publicStringNome
{
set
{
nome=value;
}
get
{
returnnome;
}
}
publicInt32Punti
{
set
{
punteggio=value;
}
get
{
returnpunteggio;
}
}
publicAtleta(Stringn,Int32p)
{
Nome=n;
Punti=p;
}
publicAtleta()
{
}
}
}
Notiamo come la classe Atleta possieda due proprietà, chiamate anche variabili, ovvero nome e punteggio, entrambe private. Essendo private non sono accessibili dall’esterno dell’oggetto, ma solo internamente. Perciò creiamo anche dei getter e setter, ovvero dei metodi che ci permettano di modificare ed interrogare le suddette proprietà; questi “metodi” appaiono come delle proprietà a loro volta, secondo lo stile di C#, e nel nostro caso sono state chiamate Nome e Punti. Faccio notare come ho chiamato Nome con la maiuscola, rispetto alla proprietà privata nome, ma nell’assegnazione di tale nomenclatura non c’è niente di speciale. Tant’è che a punteggio ho associato Punti. Diciamo che l’uso comune prevederebbe di chiamare il getter/setterPunteggio, ma non è obbligatorio.
Abbiamo inoltre creato un costruttore che accetta una stringa ed un intero che assegna a Nome e Punti, il che ci permetterà di creare degli oggetti di tipo Atleta senza dover per forza assegnare separatamente le due proprietà.
A questo punto creiamo una classe chiamata Atleti, che conterrà una lista di oggetto di tipo Atleta ed un paio di metodi per gestirli.
Vediamo i punti salienti di questa seconda classe. Anzitutto abbiamo creato una lista di oggetti di tipo Atleta:
1
List<Atleta>atleti=newList<Atleta>();
Questa è una proprietà privata della classe, quindi per poter aggiungere nuovi oggetti alla lista creiamo un metodo apposito:
1
2
3
4
5
publicvoidaddAtleta(Atletaa)
{
atleti.Add(a);
raiseNuovoAtleta();
}
Il metodo accetta un argomento di tipo Atleta, chiamato a. Poi esegue il metodo .Add() sulla lista di oggetti di tipo Atleta, aggiungendo in fondo alla lista l’ultimo oggetto. Inoltre chiama anche un “evento” personalizzato, nello specifico il metodo raiseNuovoAtleta();
Questo metodo fa parte della seguente definizione:
Con questo piccolo trucchetto creiamo un evento personalizzato sulla nostra classe, cioè diamo la possibilità di aggiungere dei metodi all’oggetto, una volta creato, che saranno richiamati all’accadere dell’evento specifico.
Cerchiamo di capire meglio questa cosa.
Immaginiamo di voler aggiungere delle funzioni specifiche ad ogni volta che viene aggiunto un nuovo atleta. L’oggetto creato da Atleti potrebbe essere il seguente:
1
staticAtletia=newAtleti();
Adesso immaginiamo di voler far sì che, ogni volta che viene aggiunto un nuovo atleta, con il seguente metodo:
1
2
Atleta tmp=newAtleta("Mario Rossi",10);
a.addAtleta(tmp);
Venga anche richiamato un metodo personalizzato, creato fuori dalla classe, che esegua delle operazioni. Nel nostro caso manda un banale messaggio a schermo:
Dopo aver visto come poter interrogare con query SQL un foglio excel, vediamo come creare una classe ad hoc che ci permetta di leggere e scrivere i dati mediante query SQL. Per farlo anzitutto aggiungiamo una nuova classe:
Premendo ALT+F11 apriamo l’editor Visual Basic, ci posizioniamo su un qualunque punto del progetto a sinistra e clicchiamo col destro (per esempio su Form), poi scegliamo Inserisci ⇒ Modulo classe. A questo punto verrà creata una nuova classe. Per rinominarla è sufficiente selezionarla e poi spostarsi nel riquadro delle proprietà.
A questo punto incolliamo dentro la classe appena creata (tenendo presente poi il nome scelto) il seguente codice:
Visual Basic
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
' funzione in input per il database, restituisce un vettore variant di dimensione n x m, dove
' n è il numero di righe lette e m il numero di colonne per riga
Faccio notare come nel metodo dbout dobbiamo fare un’operazione un po’ superflua in apparenza, ovvero contare prima le righe e le colonne, per poi ridimensionare il vettore result. Questa operazione è necessaria perché ReDim, in VBA, non permette di ridimensionare l’intera matrice (vettore di vettori), ma solo l’ultima dimensione. Quindi, per esempio, result(4,10) potrebbe diventare result(4,20), ma non result(5,10) oppure result(5,20). Un’alternativa sarebbe quella di creare una funzione che trasponga il vettore e lo modifichi, ritrasponendolo di nuovo, ma dal punto di vista del calcolo credo sarebbe molto più oneroso che fare così.
Fatto questo potremo utilizzare la nostra nuova classe nella maniera seguente.
Visual Basic
1
2
3
4
5
6
7
8
9
10
11
12
13
14
' inserimento
Dimquery AsString
query="INSERT INTO [DATI$] (ID,Nome,Città) Values (1,'Mario','Palermo')"
Dimdb AsNewDbSQL
db.dbin query
' lettura
query="SELECT * FROM [DATI$A:C]"
Dimdb AsNewDbSQL
Dimrighe AsVariant
righe=db.dbout(query)
Fori=0ToUBound(righe,1)-1
Debuig.Print righe(i,1)' 1 = prima colonna, 2 = seconda colonna, ecc.
Nexti
Una volta creata la classe può essere esportata, oppure importata nel modo seguente:
Per chi volesse è possibile scaricare la classe già pronta cliccando qui: DbSQL.zip
Approfittando della giornata innevata e di un po’ di relax ecco un piccolo esercizio in bash per “disegnare” su terminale utilizzando semplicemente spazi e cancelletti (#).
Anzitutto creiamo una serie di funzioni che ci consentano di disegnare come se si stesse lavorando su un piano cartesiano. A tale proposito cerchiamo di disegnare una parabola con la seguente funzione:
Prima di proseguire installiamo il basic calculator, che ci permetterà di effettuare calcoli matematici elementari in bash (non è indispensabile, né l’unico modo, ma per quello che vogliamo fare dovrebbe essere sufficiente):
1
sudo apt-get install bc
Una volta installato creiamo un file parabola.sh
1
sudo nano parabola.sh
Ed inseriamo dentro il seguente codice:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
#!/bin/bash
# puliamo il terminale
clear
# stabiliamo il centro degli assi cartesiani
Cx=30
Cy=30
# disegna in posizione x, y accetta due parametri
disegna(){
# moltiplichiamo la x per 2 per compensare la dimensione
# dei font del terminale
X=$(($Cx*2+$1*2))
Y=$(($Cy-$2))
Xmax=$(($Cx*4))
Ymax=$(($Cy*2))
# stampiamo a video nella posizione x, y
# un carattere asterisco * se si trova entro i limiti del grafico
# disegniamo per primo l'asse y, in modo che eventuali punti
# sovrascrivano i simboli dell'asse
for((y=-$Cy;y<$Cy;y++));do
disegna0$y"."
done
# percorriamo adesso tutti i valori interi di x
for((x=-$Cx;x<$Cx;x++));do
dx=$(($x))
#calcoliamo y = x*x - 5
dy=$(($x*$x-5))
# già che ci siamo disegniamo l'asse x
disegna$dx0"."
# disegniamo la funzione
disegna$dx$dy"#"
done
# aggiungiamo degli spazi alla fine
for((i=0;i<$Cy;i++));do
echo
done
Ricordiamoci di rendere lo scripteseguibile digitando:
1
sudo chmoda+xparabola.sh
Ed eseguiamolo:
1
./parabola.sh
Il risultato di questa operazione dovrebbe dare qualcosa di simile a questo:
Faccio notare che la funzione disegna accetta come terzo parametro il tipo di carattere che vorremo utilizzare.
Adesso che abbiamo verificato che il disegno sul piano cartesiano funziona possiamo scrivere la serie di istruzioni necessarie a generare il nostro simpatico fiocco di neve. Le funzioni matematiche necessarie le ho prese da qui: Snowflake Math.
Inutile dire che si potrebbero usare moltissime altre funzioni, oppure divertirci con un calcolo frattale. Notiamo però che il disegno accetterà solo valore naturali interi, quindi il risultato sarà comunque un po’ impreciso. Infatti non possiamo aumentare la densità di caratteri sul terminale, potendo così apprezzare altri dettagli. Lo script sarà dunque questo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
#!/bin/bash
clear
# stabiliamo il centro degli assi cartesiani per il
Problema: non sembra esserci spazio sufficiente sul disco per eseguire installazioni ed aggiornamenti con apt-get
Per risolvere il problema è sufficiente cancellare i vecchi linux-headers e linux-image del Kernel. Questi file si trovano in /usr/src/
Per verificare le versioni installate anzitutto controlliamo il contenuto della suddetta cartella con:
1
ls/usr/src/
Dovremmo vedere un elenco di file chiamati linux-headers, linux-image, linux-image-extra ed altri. Per esempio potremmo trovare un elenco come il seguente:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/usr/src/linux-headers-3.13.0-132-generic
/usr/src/linux-image-3.13.0-132-generic
/usr/src/linux-image-extra-3.13.0-132
/usr/src/linux-headers-3.13.0-132
/usr/src/linux-image-3.13.0-132
/usr/src/linux-image-extra-3.13.0-132
/usr/src/linux-headers-3.13.0-133-generic
/usr/src/linux-image-3.13.0-133-generic
/usr/src/linux-image-extra-3.13.0-133
/usr/src/linux-headers-3.13.0-133
/usr/src/linux-image-3.13.0-133
/usr/src/linux-image-extra-3.13.0-133
/usr/src/linux-headers-3.13.0-135-generic
/usr/src/linux-image-3.13.0-135-generic
/usr/src/linux-image-extra-3.13.0-135
/usr/src/linux-headers-3.13.0-135
/usr/src/linux-image-3.13.0-135
/usr/src/linux-image-extra-3.13.0-135
/usr/src/linux-headers-3.13.0-137-generic
/usr/src/linux-image-3.13.0-137-generic
/usr/src/linux-image-extra-3.13.0-137
/usr/src/linux-headers-3.13.0-137
/usr/src/linux-image-3.13.0-137
/usr/src/linux-image-extra-3.13.0-137
Nel mio caso vedo che ho installate le versioni 3.13.0-132,3.13.0-133, 3.13.0-135 e 3.13.0-137 del kernel.
Questo significa che posso cancellare, a meno di non averne bisogno per specifici motivi (ma se non li conosco, probabilmente non ne ho bisogno) le versioni 132, 133 e 135. Devo lasciare invece la versione 137.
Dopo svariate prove sono giunto alla conclusione che per cancellare una determinata versione, senza lasciare fastidiosi rimasugli, è sufficiente digitare la seguente serie di istruzioni (immaginiamo di voler eliminare la versione 132):
Per chi volesse cancellare più versioni in un colpo solo, senza stare a perdere tempo a modificare i numeri nelle precedenti righe, ho creato un piccolo script per Python (io uso questo per fare pulizia sul disco) che mi genera i comandi da incollare sul terminale.
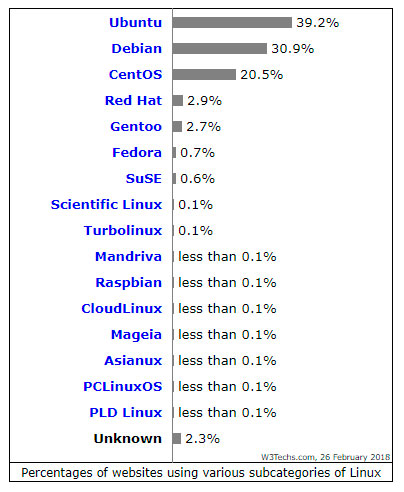
Oggi ho deciso di cimentarmi nell’installazione di quel obbrobrio modaiolo che è CentOS. Dico così perché è a tutti gli effetti utilizzato da meno del 20% dei webserver ed in generale mi sono convinto che venga scelto più per una questione di moda, che per qualche reale vantaggio rispetto ad Ubuntu/Debian.
Lungi dal voler scatenare una guerra tra distribuzioni, questo resta naturalmente un mio personalissimo parere, corroborato da “qualche” statistica (cioè non toglie, che io stesso, in momenti di malignità, abbia installato CentOS, per il morboso gusto dell’esperimento sulla pelle d’altri).
Comunque sia avventuriamoci in questo mondo e vediamo un po’ di differenze rispetto ad Ubuntu e Debian.
Anzitutto ci viene chiesto che cosa intendiamo fare, scegliamo la prima opzione (banalmente premiamo INVIO, oppure I) e proseguiamo.
A questo punto compare una schermata con interfaccia grafica dove scegliere la lingua di installazione.
Scegliamo l’italiano come nella figura seguente e poi proseguiamo.
Selezioniamo Continua e ci troviamo di fronte alla schermata di tutte le impostazioni possibili.
Notiamo come è segnalato un “problema” sulla destinazione dell’installazione, unica cosa che dobbiamo scegliere effettivamente. Tutti gli altri parametri sono preconfigurati nella versione minima predefinita e possiamo lasciarli tali. Clicchiamo quindi su destinazione di installazione.
Scegliamo il nostro disco (nel mio caso quello da 30GB) e lasciamo la configurazione automatica (come avremmo fatto per Ubuntu). Clicchiamo su FATTO.
Adesso è possibile scegliere Avvia installazione.
Mentre prosegue l’installazione, con tanto di banner pubblicitario non richiesto (e questo già la dice lunga su dove ci stiamo avventurando) possiamo configurare la password di root ed eventuali altri utenti. In questo caso creiamo soltanto il nostro utente root dandogli una password. Clicchiamo su password di root.
Se si trattasse di una vera installazione online ci converrebbe, naturalmente, scegliere una buona password. Io ne metto una semplice, che però non sia troppo semplice e venga accettata. Il fatto stesso che il sistema “protesti” all’inserimento di “password” è un altro dei punti che trovo detestabili, visto che ho scelto linux proprio per fare, e sbagliare anche, di testa mia. Ma procediamo. Io ho messo una password un po’ più complessa, anche se si tratta di un esempio.
Quando l’installazione è completata possiamo riavviare il sistema.
Adesso possiamo cominciare a lavorare.
2. Connessione in SSH e configurazione rete
Se avete scelto l’installazione minima prima di potersi collegare in SSH, dopo aver inoltrato le porte su VirtualBox, qualora stesse lavorando sotto NAT come sto facendo io, è necessario avviare il servizio di rete. Per farlo digitiamo:
1
dhclient
Senza questo servizio avviato non ci si può nemmeno collegare a internet.
Apriamo putty (o il nostro client ssh) e colleghiamoci normalmente alla macchina che abbiamo appena installato.
A questo punto impostiamo la rete perché si avvii automaticamente ad ogni riavvio del sistema (altrimenti dovremmo farlo noi a mano). Per poter modificare il file avremo bisogno di un editor di testo, quindi installiamo nano (ce ne sono anche tanti altri):
1
yum install nano
Ci verrà chiesto di confermare l’installazione e sarà sufficiente premere y o s, in base a quello che viene proposto.
Fatto questo identifichiamo la nostra scheda di rete, ifconfig non funziona perché andrebbe installato, quindi digitiamo:
1
ip addr
Nel mio caso vengono mostrate le seguenti due schede:
1
2
3
4
5
6
7
8
9
10
11
12
1:lo:<LOOPBACK,UP,LOWER_UP>mtu65536qdisc noqueue state UNKNOWN qlen1
Faccio notare che la prima interfaccia di rete è quella locale, chiamata lo, mentre la seconda è la scheda di rete della macchina virtuale (in una configurazione su macchina fisica qui avremmo eth0 probabilmente) chiamata enp0s3.
Da qui possiamo anche vedere che alla scheda di rete è stato assegnato l’indirizzo IP 10.0.2.15 (classica configurazione di VirtualBox).
Quindi andiamo a vedere i file di configurazione di rete e digitiamo:
1
ls/etc/sysconfig/network-scripts/
Questo ci mostrerà vari file di configurazione, come nella schermata seguente:
Notiamo i primi due file che hanno i nomi ifcfg-enp0s3 e ifcfg-lo. Modifichiamo quindi il file di configurazione della scheda di rete:
1
nano/etc/sysconfig/network-scripts/ifcfg-enp0s3
Ci dovremmo trovare di fronte a qualcosa di simile a questo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=dhcp
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=enp0s3
UUID=5c133616-0362-451e-adce-a6c5b5a11c90
DEVICE=enp0s3
ONBOOT=no
Modifichiamo il parametro ONBOOT=no facendolo diventare ONBOOT=yes. Salviamo premendo CTRL+O e riavviamo il computer per accertarci che sia tutto andato bene.
Per riavviare digitiamo:
1
reboot now
Se tutto è andato bene potremo accedere normalmente in SSH.
3. Installazione server LAMP
Adesso è il momento di installare il nostro server LAMP (Linux + Apache + MySQL + PHP). Anzitutto digitiamo:
1
yum install httpd
Una volta completata l’installazione dobbiamo avviare il servizio e configurare il firewall perché sia accessibile.
Quindi per avviare il servizio digitiamo:
1
2
systemctl start httpd.service
systemctl enable httpd.service
Mentre per configurare il firewall utilizziamo firewall-cmd digitando:
Faccio notare che quello che viene configurato sono 2 servizi, ovvero due porte, HTTP 80, HTTPS 443.
Andando all’indirizzo http://192.168.56.1/ (questo è il mio indirizzo della macchina virtuale) possiamo verificare che il server web funzioni correttamente (apparirà una pagina con scritto Testing 123…)
Adesso dobbiamo installare MySQL / MariaDB, MariaDB è l’evoluzione del MySQL, compatibile con quest’ultimo. Nel nostro caso installiamo MariaDB (giusto per variare un po’ sul tema, per il MySQL la procedura è analoga). Quindi digitiamo:
1
yum-yinstall mariadb-server mariadb
Faccio notare che il flag -y permette di installare tutto senza ulteriori richieste di conferma. In modo analogo a prima digitiamo poi:
1
2
systemctl start mariadb.service
systemctl enable mariadb.service
In questo modo abilitiamo ed avviamo il servizio. Adesso però dobbiamo impostare la password dell’utente principale del database, che si chiama sempre root, anche se è diverso dal root di sistema. Oltre a questo vogliamo configurare alcuni parametri di sicurezza. Digitiamo:
1
mysql_secure_installation
Verranno poste le seguenti domande:
Enter current password for root (enter for none): PREMIAMO INVIO, non c’è nessuna password di root per ora
Set root password? [Y/n]: Y
New password: METTIAMO UNA PASSWORD
Re-enter new password: RIPETIAMO LA SUDDETTA PASSWORD
Remove anonymous users? [Y/n] Y
Disallow root login remotely? [Y/n] Y
Remove test database and access to it? [Y/n] Y
Reload privilege tables now? [Y/n] Y
In questo modo abbiamo messo in sicurezza e configurato il nostro database.
Adesso è il turno del PHP. Per assicurarci di scaricare la versione più recente, ovvero il PHP7, aggiorniamo la repository.
A questo punto comincia una piccola avventura degna solo di CentOS. Anzitutto bisogna abilitare il PHP affinché venga eseguito dal motore php-fpm (il PHP è un linguaggio compilato sul momento e può essere eseguito da diversi motori). Per qualche ragione l’installazione con yum non si occupa di questa cosa. Spostiamoci quindi in /etc/httpd/conf.d/ dove andremo a creare un file di configurazione chiamato fpm.conf. Attenzione, nel nome non c’è niente di speciale, poteva anche essere ilmiophp.conf. L’importante è l’estensione *.conf. Digitiamo quindi:
In questo modo reindirizziamo le richieste dei documento PHP al server fcgi.
A questo punto dobbiamo avviare il servizio e riavviare Apache, digitando la seguente serie di comandi:
1
2
3
4
systemctl enable rh-php70-php-fpm.service
systemctl start rh-php70-php-fpm.service
systemctl enable httpd
systemctl start httpd
Eventualmente, se avessimo bisogno, possiamo visualizzare lo stato del servizio fpm-php digitando:
1
systemctl status rh-php70-php-fpm.service
A questo punto creiamo la nostra solita pagina PHP di prova in /var/www/html (stesso percorso predefinito di Ubuntu):
1
nano/var/www/html/index.php
Dentro il file incolliamo:
1
2
3
4
5
<?php
phpinfo();
?>
Salviamo premendo come al solito CTRL+O.
Adesso apriamo la nostra pagina web al solito indirizzo di prima http://192.168.56.1/. Quello che vediamo, per la nostra massima felicità, è quanto segue:
Questo dipende dal fatto che abbiamo creato il file index.php come root, e non gli abbiamo assegnato l’utente di Apache. Per farlo anzitutto controlliamo l’utente con cui gira Apache aprendo:
1
nano/etc/httpd/conf/httpd.conf
Scendendo nel file vedremo una voce simile a questa:
1
2
3
4
5
6
7
8
9
10
#
# If you wish httpd to run as a different user or group, you must run
# httpd as root initially and it will switch.
#
# User/Group: The name (or #number) of the user/group to run httpd as.
# It is usually good practice to create a dedicated user and group for
# running httpd, as with most system services.
#
User apache
Group apache
In questo caso (ma è così di solito) il nostro utente è apache ed il gruppo è apache. Quindi modifichiamo i permessi sul file appena creato:
1
chown apache:apache/var/www/html/index.php
A questo punto ricontrolliamo e scopriamo due cose:
1. l’errore si presenta uguale a prima
2. la guida di CentOS stesso fa totalmente schifo. Le istruzioni da incollare dentro ad fpm.conf le ho infatti copiate da qui, quello che però non viene detto è che andrebbe anche configurato index.php come pagina predefinita, altrimenti apache pensa che, non essendoci una index.html, non si possa accedere alla cartella
Quindi digitiamo:
1
nano/etc/httpd/conf.d/fpm.conf
E modifichiamo il file di prima in modo tale che risulti così (ho aggiunto solo l’ultima riga):
Adesso però verifichiamo se è andato davvero tutto bene collegandoci anche al database. Anzitutto creiamo un nuovo database.
Per farlo accediamo al MySQL/MariaDB che abbiamo installato prima. Digitiamo:
1
mysql-uroot-p
Attenzione! La medesima istruzione va digitata anche nel caso che si stia usando MariaDB, come sto facendo io, che vi ricordo è un aggiornamento di MySQL perfettamente retrocompatibile.
Digitiamo la password del database e ci troviamo nella console di gestione di MariaDB, che appare così:
1
MariaDB[(none)]>
Questo significa che non abbiamo selezionato alcun database. Adesso creiamo un database (io lo chiamerò petar):
1
CREATE DATABASE petar;
Proviamo anche a creare un utente chiamato petar e che possa accedere a tale database solamente da localhost (quindi da connessione locale). Per farlo digitiamo:
1
2
CREATE USER petar@localhost IDENTIFIED BY'password123';
GRANT ALL PRIVILEGES ON petar.*TOpetar@localhost;
La password per il nuovo utente sarà password123. Per uscire dalla console del MariaDB digitiamo:
1
exit
Adesso torniamo sul nostro file /var/www/html/index.php di prima e modifichiamolo nella maniera seguente:
Se abbiamo fatto tutto bene andando su http://192.168.56.1/ vedremo qualcosa di simile a questo:
In caso che ci sia stato qualche errore (possiamo riprodurlo di proposito sbagliando la password nel suddetto codice php) dovremmo vedere qualcosa di simile:
Accertiamoci anche che, modificando il codice in questo modo:
In entrambi i casi, affinché le modifiche abbiano successo, è necessario riavviare il firewall:
1
firewall-cmd--reload
Tutto questo è molto bello, ma sinceramente preferisco lavorare con iptables. Ricordiamoci che sia firewalld che iptables sono due software, distinti, che gestiscono il firewall vero che si chiama netfilter. Per verificare che sia installato, dovrebbe esserlo, digitiamo:
1
rpm-qiptables
Il risultato dovrebbe essere qualcosa come: iptables-1.4.21-18.2.el7_4.x86_64
Questo ci indica l’ultima versione installata. Controlliamo quindi, con iptables, qual’è la configurazione attuale.
1
iptables-L
Quello che viene fuori è un casino simile a questo:
ACCEPT tcp--anywhere anywhere tcp dpt:ssh ctstate NEW
ACCEPT tcp--anywhere anywhere tcp dpt:https ctstate NEW
ACCEPT tcp--anywhere anywhere tcp dpt:http ctstate NEW
Chain IN_public_deny(1references)
target prot opt source destination
Chain IN_public_log(1references)
target prot opt source destination
Chain OUTPUT_direct(1references)
target prot opt source destination
Personalmente trovo tragicomico che un’installazione minima di CentOS parta con una simile configurazione di iptables (e soprattutto parta con aperta solamente la porta SSH). Essendo un’installazione minima ci si potrebbe aspettare che il firewall non sia configurato e che tutte le porte siano aperte, per poi dovercene occupare noi.
Per tanto, siccome voglio avere una visione chiara della situazione del firewall, resetto tutto quanto impostando aperte solo le porte per SSH, HTTP e HTTPS. Per farlo mi è sufficiente eseguire il seguente codice da terminale (va bene anche un copia/incolla)
Il risultato di questa purga, digitando iptables -L, dovrebbe essere così:
1
2
3
4
5
6
7
8
9
10
11
12
Chain INPUT(policy DROP)
target prot opt source destination
ACCEPT tcp--anywhere anywhere tcp dpt:http
ACCEPT tcp--anywhere anywhere tcp dpt:https
ACCEPT tcp--anywhere anywhere tcp dpt:ssh
ACCEPT all--anywhere anywhere state RELATED,ESTABLISHED
Chain FORWARD(policy DROP)
target prot opt source destination
Chain OUTPUT(policy ACCEPT)
target prot opt source destination
Per salvare la configurazione dobbiamo installare i servizi di iptables digitando:
1
yum install iptables-services
Abilitiamo il servizio digitando:
1
systemctl enable iptables
Già che ci siamo sbarazziamoci di firewalld:
1
2
systemctl stop firewalld
systemctl mask firewalld
Riavviamo il servizio iptables (fino ad ora abbiamo usato solo il programma client):
1
systemctl restart iptables
E infine salviamo:
1
service iptables save
A questo punto dovremmo ricevere una conferma di questo tipo:
Per accertarci che tutto sia andato bene possiamo riavviare l’intera macchina con un reboot now e ricontrollare lo stato del firewall digitando iptables -L.
5. Installazione di fail2ban
Come ultima operazione installiamo fail2ban, onde limitare le possibilità di ricevere attacchi sulla porta 22 del protocollo SSH. In questo modo evitiamo che si possano fare numerosi tentativi per scoprire i dati di accesso, bannando via via gli indirizzi IP da cui arrivano gli attacchi.
Per installare fail2ban anzitutto aggiungiamo il pacchetto EPEL Project alla nostra repository.
1
sudo yum install epel-release
Qualora risultasse già installato tanto meglio. Procediamo installando fail2ban:
Adesso configuriamo il programma. Per farlo possiamo modificare alcuni file. In particolare teniamo presente le seguenti cose:
/etc/fail2ban/jail.conf questo il primo file di configurazione, è quello predefinito, lo possiamo modificare, ma se vogliamo fare un lavoro pulito ci conviene lasciarlo così com’è
/etc/fail2ban/jail.d/*.conf, questi sono i file *.conf predefiniti, vengono accorpati al file precedente, sostituendo eventuali parametri equivalenti, anche questi file possono essere lasciati intatti così come sono
/etc/fail2ban/jail.local questo è il file di configurazione locale, segue ai due file precedenti, e quindi ogni modifica apportata qui dentro potrà sovrascrivere le precedenti
/etc/fail2ban/jail.d/*.local, infine questa è la cartella nella quale si troveranno i file *.local personalizzati che andranno a sostituire quelli precedenti e verranno accorpati in ordine alfabetico
Quindi anzitutto impostiamo i parametri base per fail2ban modificando il seguente file:
1
nano/etc/fail2ban/jail.local
Il file risulterà vuoto, quindi ci possiamo incollare dentro i seguenti parametri. Questi andranno a sostituire quelli di default.
1
2
3
4
[DEFAULT]
bantime=3600
maxretry=3
banaction=iptables-multiport
A questo punto creiamo un file per l’SSH digitando:
1
nano/etc/fail2ban/jail.d/ssh.local
Ricordiamoci che i file verranno letti in ordine alfabetico, nel nome del file, a parte l’estensione *.local, non c’è niente di speciale. Si poteva anche chiamare 001-config.local.
1
2
3
4
5
[sshd]
port=ssh
enabled=true
maxretry=3
Salviamo e riavviamo fail2ban:
1
systemctl restart fail2ban
Verifichiamo la situazione digitando:
1
fail2ban-client status
Ci dovrebbe comparire qualcosa di simile:
Notiamo che è abilitata una jail per l’sshd. Stessa verifica la possiamo fare su iptables digitando iptables -L e controllando la presenza di una chain per fail2ban.
Per accertarci che tutto vada bene possiamo tentare di accedere in SSHsbagliando password. Inutile dire che una volta bannati dovremo poter accedere direttamente alla macchina per sbannarci.
Per visualizzare gli ip bannati è sufficiente digitare (per la chain f2b-sshd creata fa fail2ban dentro al firewall):
1
iptables-Lf2b-sshd-v-n
In questo caso il mio IP è il 10.0.2.2 e possiamo notare che appare tra quelli bannati:
Per rimuoverlo, ovvero sbloccare l’indirizzo ip bannato, basta digitare:
1
sudo fail2ban-client set sshd unbanip10.0.2.2
A questo punto possiamo accedere nuovamente mediante SSH.
Adesso abbiamo configurato CentOS per essere pronto ed operativo come server LAMP.
Obiettivo: configurare il firewall su Ubuntu adatto ad un webserver, compresi servizi FTP e di posta, capendo come funzionano le regole ed i criteri principali
Suggerimento: per testare la connessione possiamo usare il webserver creato con Apache e provare via via a collegarci alla porta 80, ovvero all’indirizzo del server tramite browser. Nell’esempio dell’altra volta tale indirizzo era http://192.168.56.1
Iptables è un programma che serve a gestire Netfilter, che è il vero firewall della maggior parte dei più moderni sistemi Linux. Su Wikipedia ci sono maggiori dettagli di base, per ora ne estraggo la citazione fondamentale:
Per configurare netfilter attualmente si usa il programma iptables, che permette di definire le regole per i filtri di rete e il reindirizzamento NAT. Spesso con il termine iptables ci si riferisce all’intera infrastruttura, incluso netfilter.
Iptables si basa su 3 catene principali:
INPUT traffico in entrata, per esempio collegarsi da fuori verso il PC in SSH oppure interrogare il server web in HTTP
FORWARD traffico reindirizzato, si usa solo nel caso in cui il PC effettui operazioni di routing
OUTPUT connessioni in uscita, per esempio operazioni di ping
E 3 criteri fondamentali:
ACCEPT permette
DROP blocca come se non esistesse
REJECT blocca inviando un errore
Ci sono anche altri criteri, ma per ora focalizziamoci su questi che sono essenziali per i nostri scopi.
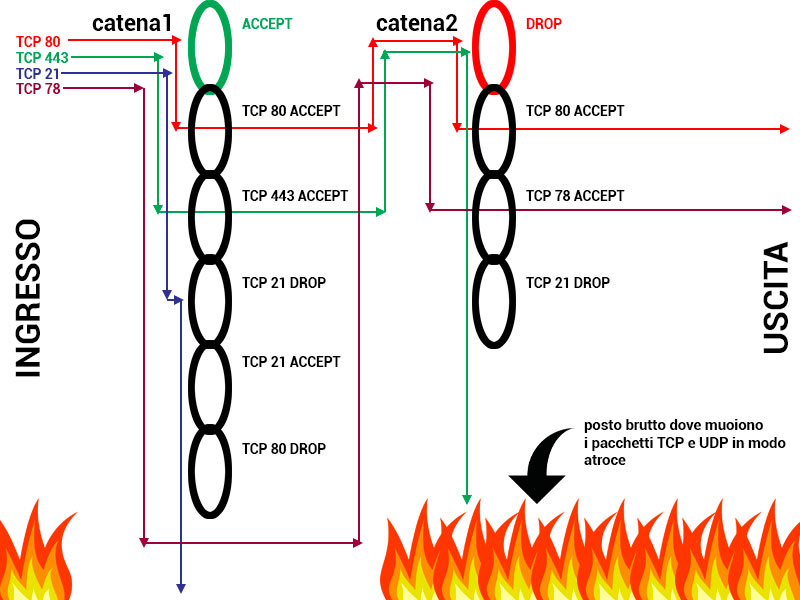
Prima di proseguire capiamo meglio come funzionano le catene (chain). Sul firewall possono essere configurate diverse catene, che verranno visitate nell’ordine in cui sono inserite.
Immaginiamo di avere del traffico in ingresso e due catene come di seguito:
Alle catene vengono aggiunti anelli successivi, allungandole sempre di più. Un pacchetto che entra cerca di passare da un anello dove gli sia consentito, altrimenti, se non trova passaggi liberi, viene scartato. Per riuscire ad attraversare “indenne” il firewall deve visitare tutte le catene successive (devono essere referenziate, ma questo lo vedremo dopo).
Il primo anello rappresenta il criterio generale della catena, ma anche questo lo capiremo meglio dopo.
Questa è una spiegazione vagamente semplicistica, ma per il momento è sufficiente.
NOTA: E’ molto importante ricordare che mentre si apportano le modifiche ad iptables queste non saranno permanente finché non si salvano definitivamente; questo significa che se aggiungiamo dei criteri e poi riavviamo il computer, al riavvio questi non saranno più presenti. Perché diventino permanenti bisogna salvarli e vedremo come dopo.
1. Visualizzare lo stato del firewall (iptables)
Per visualizzare la configurazione del firewall è sufficiente digitare:
1
sudo iptables-L
Nel mio caso viene visualizzato qualcosa di simile (ho già effettuato delle configurazioni):
Notiamo che nella prima chain, quella di INPUT (le prime 3 sono predefinite), c’è un comando inutile che tenta di bloccare i pacchetti dpt:http (dpt = destination port, http = 80), ovvero quelli passanti dalla porta 80 utilizzata per le connessioni web HTTP. Poche righe prima è infatti definita una regola che li fa passare attraverso la catena con ACCEPT, quindi questo DROP è inutile.
2. Accettare tutte le connessioni e ripristinare il firewall alla configurazione base
Per fare il reset del firewall è sufficiente digitare:
1
sudo iptables-F
La -F sta per flush. Questo reimposterà tutte le catene effettuando la cancellazione di tutti gli anelli, lasciando solamente quelli in cima. Questo significa che se la regola per INPUT è ACCEPT resterà ACCEPT, se fosse stata DROP resterà DROP, senza tutte le altre regole a seguire.
Per reimpostare il primo anello della catena è necessario utilizzare:
1
sudo iptables-PINPUT ACCEPT
In questo caso modifichiamo la catena predefinita degli INPUT, impostandola affinché faccia passare tutte le connessioni che non sono state definite. Il primo anello della catena, nel disegno precedente, è il criterio della catena.
Digitando il seguente comando si aprirà l’intero firewall e si cancelleranno tutti i criteri aggiuntivi.
1
2
3
4
sudo iptables-F
sudo iptables-PINPUT ACCEPT
sudo iptables-PFORWARD ACCEPT
sudo iptables-POUTPUT ACCEPT
Per non rischiare che il flush chiuda la connessione SSH possiamo concatenare i comandi con &&.
Immaginiamo di prendere la configurazione del firewall nel primo grafico, ma di cambiare il criterio della prima catena da DROP ad ACCEPT. Il risultato produrrà qualcosa di simile:
Quando il criterio della catena è ACCEPT significa che ogni pacchetto che non sia proibito, oppure sia esplicitamente accettato, passa, ovvero è ACCEPT di default. Se un pacchetto è DROP, al primo DROP è DROP per tutta la catena.
Per modificare il criterio di una catena, come quella di INPUT per esempio, è sufficiente digitare:
1
sudo iptables-PINPUT ACCEPT
In questo caso l’intera catena è su ACCEPT come la catena1 del disegno. Se su INPUT volessimo riprodurre le medesime regole della catena precedente sarebbe sufficiente digitare, in questo ordine:
1
2
3
4
5
sudo iptables-AINPUT-ptcp--dport80-jACCEPT
sudo iptables-AINPUT-ptcp--dport443-jACCEPT
sudo iptables-AINPUT-ptcp--dport21-jDROP
sudo iptables-AINPUT-ptcp--dport21-jACCEPT
sudo iptables-AINPUT-ptcp--dport80-jDROP
Con -Aaggiungiamo un filtro (un anello) ad INPUT (o una catena scelta), -p definisce il protocollo da filtrare, per noi TCP, –dport definisce la porta di destinazione, per esempio la porta 80, -j imposta il jump, ovvero se si passa o si precipita.
NB: i protocolli accettati sono tcp, udp, udplite, icmp, esp, ah, sctp oppure all per prenderli tutti
Per visualizzare la configurazione digitiamo:
1
sudo iptables-L
Il risultato assomiglierà al seguente:
Inutile dire come il criterio ACCEPT presupporrebbe di dover bloccare tutti i pacchetti eccetto quelli desiderati, quindi si preferisce di solito il criterio DROP, per cui sono bloccati tutti i pacchetti eccetto quello desiderati.
Il criterio ACCEPT è invece molto utile in fase di configurazione.
Immaginiamo di voler attivare il firewall solamente sulle seguenti porte: 80, 443, 20, 21, 22 (rispettivamente HTTP, HTTPS, FTP, FTP, SSH). Digitiamo in sequenza:
1
2
3
4
5
6
7
sudo iptables-PINPUT ACCEPT
sudo iptables-AINPUT-ptcp--dport80-jACCEPT
sudo iptables-AINPUT-ptcp--dport443-jACCEPT
sudo iptables-AINPUT-ptcp--dport20-jACCEPT
sudo iptables-AINPUT-ptcp--dport21-jACCEPT
sudo iptables-AINPUT-ptcp--dport22-jACCEPT
sudo iptables-PINPUT DROP
Interrogando iptables il risultato sarà:
4. Aggiungere una nuova catena personalizzata
Oltre alle catene predefinite, per ora abbiamo visto INPUT, OUTPUT e FORWARD, possiamo aggiungere delle ulteriori catene personalizzate.
Creiamo anzitutto la nostra nuova catena che io chiamerò Cerberus (niente di speciale nel nome, giusto per dare un tono fantasy all’esempio)
1
sudo iptables-NCerberus
Adesso aggiungiamo, alla catena delle regole, ma prima di tutto una confessione:
ATTENZIONE! Solamente le catene predefinite possono avere dei criteri come ACCEPT, DROP, REJECT ecc., le catene personalizzate non possono averli, ma vanno collegate a quelle predefinite
Quindi sulla nostra catena personalizzata Cerberus blocchiamo la porta 80.
1
sudo iptables-ACerberus-ptcp--dport80-jDROP
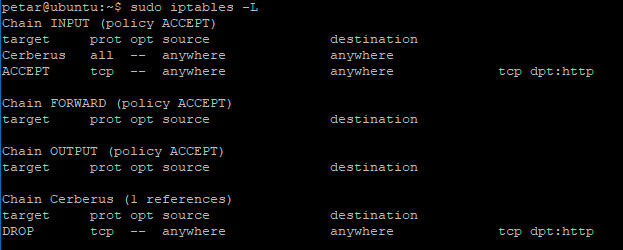
Assicuriamoci che la catena INPUT sia sul criterio ACCEPT e senza altri filtri. In tal caso il nostro server è ancora accessibile sulla porta 80.
Adesso colleghiamo la catena Cerberus alla catena predefinita INPUT, inserendo un jump (un salto potremmo dire)
1
sudo iptables-AINPUT-jCerberus
A questo punto il server non è più accessibile dalla porta 80.
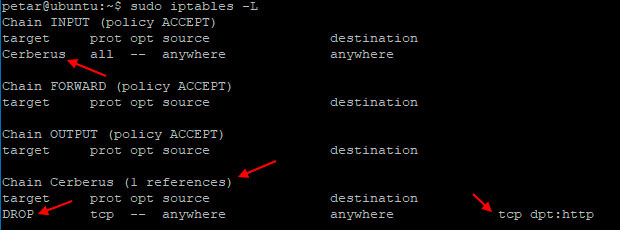
Se interroghiamo iptables per vedere le configurazioni presenti, vedremo qualcosa come questo:
Faccio notare come alla chain Cerberus è segnato un riferimento (1 references)
Per rimuovere il riferimento, e quindi riattivare la porta 80, è sufficiente eseguire:
1
sudo iptables-DINPUT-jCerberus
ATTENZIONE! Bisogna tenere conto dell’ordine della catena e dove viene collegata ogni nuova catena. Immaginiamo di eseguire i seguenti comandi:
1
2
3
4
sudo iptables-PINPUT ACCEPT
sudo iptables-F
sudo iptables-AINPUT-ptcp--dport80-jACCEPT
sudo iptables-AINPUT-jCerberus
In questo modo ripristiniamo tutta la catena INPUT, impostando il criterio su ACCEPT, quindi permettiamo l’uscita dei pacchetti sulla porta 80. In questo caso, la catena Cerberus non serve a nulla.
5. Cambiare ordine ai filtri (anelli) sulla catena
Benché sia possibile eliminare i singoli filtri, non è possibile ordinarli. Esiste però un trucco, ed il seguente:
1
sudo iptables-save>iptables.txt
Questo creerà un file iptables.txt nella posizione nella quale ci troviamo. Apriamo e modifichiamo il file:
1
sudo nano iptables.txt
Quello che ci verrà mostrato è il set di tutte le regole impostate nel firewall. Nel mio caso, dopo le ultime modifiche le regole saranno:
1
2
3
4
5
6
7
8
9
10
11
12
# Generated by iptables-save v1.6.0 on Sat Feb 24 02:19:51 2018
*filter
:INPUT ACCEPT[442:29268]
:FORWARD ACCEPT[0:0]
:OUTPUT ACCEPT[283:46775]
:Cerberus-[0:0]
:f2b-sshd-[0:0]
-AINPUT-ptcp-mtcp--dport80-jACCEPT
-AINPUT-jCerberus
-ACerberus-ptcp-mtcp--dport80-jDROP
COMMIT
# Completed on Sat Feb 24 02:19:51 2018
A questo punto modifico il file invertendo tra di loro la riga 8 e la 9, ottenendo il seguente file:
1
2
3
4
5
6
7
8
9
10
11
12
# Generated by iptables-save v1.6.0 on Sat Feb 24 02:19:51 2018
*filter
:INPUT ACCEPT[442:29268]
:FORWARD ACCEPT[0:0]
:OUTPUT ACCEPT[283:46775]
:Cerberus-[0:0]
:f2b-sshd-[0:0]
-AINPUT-jCerberus
-AINPUT-ptcp-mtcp--dport80-jACCEPT
-ACerberus-ptcp-mtcp--dport80-jDROP
COMMIT
# Completed on Sat Feb 24 02:19:51 2018
A questo punto salviamo il file ed importiamolo nel firewall digitando:
1
sudo iptables-restore<iptables.txt
Adesso controllando di nuovo la configurazione del firewall vedremo:
Adesso possiamo verificare che la porta 80 sia bloccata.
ATTENZIONE! Ricordarsi di cancellare il file iptables.txt se non si trova in un posto sicuro.
6. Eliminare un filtro (anello) della catena
Per eliminare un singolo filtro della catena è sufficiente dichiararlo al “contrario”. Se per esempio per aggiungere il suddetto filtro sulla porta 80 abbiamo digitato:
1
sudo iptables-AINPUT-ptcp--dport80-jACCEPT
Per rimuoverlo è sufficiente digitare:
1
sudo iptables-DINPUT-ptcp--dport80-jACCEPT
Faccio notare che l’unico parametro che cambia è la -A che diventa -D, che starebbe per delete, ovvero cancella.
La rimozione può essere anche effettuata in base al numero di riga nella catena interessata. La prima riga equivale ad 1.
Infine un modo ancora più veloce è quello illustrato al punto 5 per ordinare le regole, semplicemente rimuovendole dal file di testo e reimportandolo.
7. Aggiungere intervalli di porte ad iptables
Per aggiungere un intervallo di porte, per esempio dalla 6000 alla 6010, è sufficiente digitare:
1
sudo iptables-AINPUT-ptcp--dport6000:6010-jACCEPT
Se si interroga iptables all’intervallo scelto si potrebbe vedere qualcosa di simile:
1
ACCEPT tcp--anywhere anywhere tcp dpts:x11:6010
Nella colonna finale notiamo dpts che sta per destination ports, x11 che è il nome della porta 6000, utilizzata da X Windows System. Se la porta non avesse avuto un nome sarebbe comparso il numero.
Se volessimo invece abilitare diverse porte contemporaneamente sarebbe sufficiente digitare:
Questo bloccherà tutte le connessioni sulla porta 80, eccetto quelle provenienti dall’indirizzo 10.0.2.2.
9. Firewall su OUTPUT
Potremmo dire, per semplificare l’idea, che mentre le regole di INPUT si applicano al modello client ⇒ server (noi siamo il server) quelle di OUTPUT si applicano server ⇒ client. Ovvero al momento in cui il nostro server cerca di uscire verso l’esterno.
Questo avviene praticamente in tutte le connessioni, per esempio quando ci colleghiamo in SSH noi dobbiamo poter parlare da fuori al server (client ⇒ server), ma il server deve anche poterci rispondere (server ⇒ client).
Se digitassimo:
1
sudo iptables-POUTPUT DROP
Praticamente nulla uscirebbe dal server.
Per capire meglio questa cosa proviamo a fare la seguente prova. Anzitutto assicuriamoci che l’OUTPUT non abbia filtri e sia su ACCEPT.
Proviamo a scaricare un file sul nostro server (per esempio il file zip di installazione di WordPress). Digitiamo:
1
wget https://wordpress.org/latest.tar.gz
Questo scaricherà nella cartella dove ci troviamo un file chiamato latest.tar.gz.
In questo momento non ci interessa tanto il file quanto il fatto che possa scaricarlo. Adesso proviamo a digitare i seguenti due comandi:
Questo aggiungerà due regole, la prima, che abbiamo già visto, per mantenere aperte le connessioni stabilite, la seconda per bloccare tutte le altre connessioni dall’interno. Questo significa che se un client interroga il server, quindi stabilisce una connessione del tipo client ⇒ server (come quando accediamo con putty al server), allora anche la relativa connessione server ⇒ client necessaria sarà permessa. Altrimenti sarà impossibile collegarsi da dentro al server verso l’esterno.
Se adesso tentiamo il comando precedente:
1
wget https://wordpress.org/latest.tar.gz
Incontriamo il seguente errore:
1
2
Risoluzione di wordpress.org(wordpress.org)...non riuscito:Errore temporaneo nella risoluzione del nome.
Questa connessione dovrebbe avvenire sulla porta 443 (HTTPS) quindi possiamo provare ad aprirla digitando:
1
sudo iptables-AOUTPUT-ptcp--dport443-jACCEPT
Ma anche così facendo il download si blocca sulla risoluzione del dominio. Questo avviene perché il server deve potersi connettere anche in TCP e UDP al DNS sulla porta 53. Quindi è necessario abilitare anche tale filtro digitando:
1
2
sudo iptables-AOUTPUT-ptcp--dport53-jACCEPT
sudo iptables-AOUTPUT-pudp--dport53-jACCEPT
A questo punto il download può avvenire.
Inutile dire che mantenere questo genere di blocco è di scarso interesse quando siamo noi i soli a gestire il server.
10. Configurare il firewall standard per server web con Apache, Webmin, FTP, POP3, SMTP, IMAP e SSH
Fatti tutti questi esperimenti scriviamo la configurazione per il nostro firewall standard, aprendo le porte per i suddetti servizi:
Le uniche porte non predefinite sono quelle per l’FTP passivo che ho messo, giusto per prova, dalla 6000 alla 6010. In realtà converrebbe associare un range più ampio, in base anche al numero di connessioni che si intende ricevere.
Per salvare il tutto installiamo iptables-persistent (se non lo abbiamo già fatto):
1
sudo apt-get install iptables-persistent
Ed infine digitiamo:
1
sudo netfilter-persistent save
Vi ricordate che netfilter è il vero firewall di Linux e iptables “solo” un programma di gestione? Questo comando salva tutti i dati che abbiamo configurato.
L’esercizio in bash che propongo stavolta consiste nell’automatizzare la configurazione di un hosting sul nostro server Apache, ovvero la configurazione del VirtualHost, di un nuovo utente e database MySQL e di un accesso FTP.
L’obiettivo è quello di arrivare ad avere uno script utilizzabile nel modo seguente:
I parametri che vogliamo passare al nostro script sono:
-u: il nome dell’utente che vogliamo creare
-d: il nome del dominio che vogliamo registrare come VirtualHost di Apache
–dbadmin: il nome utente dell’amministratore del database, quello in grado di creare altri utenti all’interno del MySQL
–dbpass: la password del suddetto utente del database MySQL
Questo ci darà occasione per esplorare diverse caratteristiche di bash.
Anzitutto vogliamo acquisire ed elaborare i vari parametri passati al nostro script. Finora abbiamo visto che i parametri possono essere letti usando $# per contare il numero di argomenti, $0 per visualizzare il nome dello script, $1 per prendere il primo parametro, $2 per prendere il secondo e via discorrendo.
Adesso vogliamo prendere un numero indefinito di argomenti e parametrizzarli, vediamo come fare:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
while[[$# -gt 0 ]]
do
parametro="$1"
case$parametro in
-d|--domain)
dominio="$2"
shift
shift
;;
-u|--user)
utente="$2"
shift
shift
;;
--dbadmin)
dbadmin="$2"
shift
shift
;;
--dbpass|--dbpassword)
dbpass="$2"
shift
shift
;;
-h|--help)
aiuto=true
shift
;;
-f|--fix)
ripristina=true
shift
;;
*)
shift
;;
esac
done
Usiamo quindi un ciclo while che continuerà ad andare avanti finché il numero di parametri passati allo script non sarà 0. Quindi acquisiamo il primo parametro $1 e lo passiamo ad una variabile chiamata parametro. Utilizziamo adesso un interruttore (case…esac) per cui in base al valore di parametro si attiveranno diverse opzioni.
Ciascuna opzione è scritta nella forma
1
2
3
4
valore)
...
...
;;
Qui al posto di valore può essere un singolo valore oppure un gruppo diviso da |, nella maniera di valore1|valore2. Al posto dei puntini ci va del codice a piacere che vogliamo attivare in base alla variabile. Il principio, concettualmente, è identico a quello della realizzazione del programma in bash con menu.
Il comando shift, in bash, rimuove gli argomenti passati ad uno script a partire dall’inizio della lista, cioè dal primo argomento. Questo significa che ad ogni ciclo del while non prenderemo il primo argomento, lo controlleremo e poi lo rimuoveremo dall’elenco. Quando si digita due volte shift, si estraggono due parametri.
Viene da se che se l’argomento $1 è, per esempio, uguale a “-d“, allora l’argomento $2 dovrà contenere il nome del dominio e quindi una volta letti li rimuoveremo entrambi.
Se invece l’argomento $1 fosse uguale a “-h” oppure a “–help“, allora visualizzeremmo, senza ulteriori opzioni, una guida allo script. In questo caso dovremmo rimuovere un solo argomento.
Fatto questo cominciamo ad elaborare i parametri acquisiti. Anzitutto controlliamo se sia stato passato un nome utente del database:
1
2
3
4
5
6
7
8
call_check_dbadmin(){
if[[$dbadmin=""]]
then
errore"Inserire utente amministratore del database"
fi
}
Se non c’è un nome utente del database chiamiamo una funzione che stampi l’errore:
1
2
3
4
5
6
errore(){
echo-e"${ROSSO}ERRORE!${NC} $1. Per aiuto usare -h o --help"
exit
}
In questo caso vogliamo usare, visto che possiamo, anche dei colori, e quindi colorare di rosso la parola “ERRORE!”. Per farlo facciamo riferimento all’ANSI escape code.
Quindi possiamo usare le seguenti combinazioni:
1
2
3
4
5
6
7
8
Black0;30Dark Gray1;30
Red0;31Light Red1;31
Green0;32Light Green1;32
Brown/Orange0;33Yellow1;33
Blue0;34Light Blue1;34
Purple0;35Light Purple1;35
Cyan0;36Light Cyan1;36
Light Gray0;37White1;37
Questo significa che se nella string “ERRORE! C’è un errore” fosse scritto “\033[0;31mERRORE!\033[0m C’è un errore” la stringa verrebbe colorata tutta di rosso, fino al nuovo colore che è, in questo caso, quello nullo predefinito. Ovvero così:
Per comodità vogliamo parametrizzare alcuni colori inserendo, in cima allo script il seguente codice:
1
2
3
4
GIALLO='\033[1;33m'
ROSSO='\033[0;31m'
CELESTE='\033[1;34m'
NC='\033[0m'
La variabile NC starebbe per No Color, ovviamente i nomi sono a piacere.
Fatto questo controlliamo se sia stata passata anche la password, se non è stato fatto la richiediamo:
1
2
3
4
5
6
7
8
9
10
call_check_dbpass(){
if[[$dbadmin!=""&&$dbpass=""]]
then
echo-n"$dbadmin password: "
read-sdbpass
echo
fi
}
Potremmo aggiungere altri controlli (per esempio sul nome del dominio, ecc.) ma per ora tralasciamo ed andiamo a creare la cartella del vhost sotto a /var/www.
1
2
3
4
5
6
7
www="/var/www/"
call_crea_cartella(){
mkdir$www$dominio2>/dev/null||errore"Permesso negato. Eseguire come root"
}
Utilizziamo 2>/dev/null per reindirizzare l’output di un eventuale errore e non mostrarlo a schermo, mentre il connettore || vuol dire che, dati due comandi A e B per cui A || B, se A non va a buon fine, allora esegui B.
Fatto questo creiamo subito l’utente FTP dedicato e la relativa password. In questo esempio do per scontato che abbiamo installato ProFTPd e che sia già stato configurato correttamente sul nostro server:
1
2
3
4
5
6
7
8
9
10
11
ftppassword="$(openssl rand -base64 12)"
call_crea_ftp(){
useradd--shell/bin/false$utente
chown$utente:www-data$www$dominio
usermod-d$www$dominio$utente
echo$utente:$ftppassword|/usr/sbin/chpasswd
echo"FTP Password: $ftppassword"
}
Con il primo comando creiamo una password casuale di 12 caratteri.
Creiamo poi un utente chiamato come da argomento e assegniamo, alla cartella creata in precedenza, come proprietario l’utente appena creato e come gruppo www-data (ricordiamoci che sulla cartella deve poter interagire anche Apache). Fatta questa modifica con il comando usermod -d assegniamo la cartella alla home dell’utente. Questo viene fatto per motivi di sicurezza, per cui l’utente che accede al FTP acceda direttamente alla sua “home“, corrispondente anche allo spazio web.
Dopodiché impostiamo la password appena creata come password del nostro utente, ed infine stampiamola a video.
Faccio notare che perché –shell /bin/false non dia problemi, così come la questione della home, è necessario che nel file di configurazione di ProFTPd (/etc/proftpd/proftpd.conf) siano presenti i seguenti parametri così configurati (tipicamente va tolto il cancelletto):
1
2
DefaultRoot~
RequireValidShell off
Fatto questo scriviamo il nostro file del VirtualHost:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
sites="/etc/apache2/sites-available/"
call_crea_vhost(){
cat<<EOF>"${sites}${dominio/./_}.conf"
<VirtualHost *:80>
ServerName$dominio
ServerAdminwebmaster@localhost
DocumentRoot$www$dominio
ErrorLog\${APACHE_LOG_DIR}/error.log
CustomLog\${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
EOF
}
In questo caso vogliamo creare un file del tipo nomedominio.conf dentro a /etc/apache2/sites-available/, già che ci siamo sostituiamo il . con un _, in modo tale che nomedominio.com diventi nomedominio_com e il nome del file nomedominio_com.conf. Con l’istruzione EOF possiamo scrivere direttamente dentro il file il testo contenuto in mezzo.
Fatto questo ricarichiamo Apache:
1
2
3
4
5
6
call_agg_vhost(){
a2ensite"${dominio/./_}"2>/dev/null||errore"Apache non è installato o configurato correttamente."
service apache2 reload2>/dev/null
}
Adesso ci manca solamente il database:
1
2
3
4
5
6
7
8
9
10
11
12
13
newpassword="$(openssl rand -base64 12)"
call_crea_db(){
dbname="${dominio/./_}"
dbname="${dbname/-/_}"
mysql-u$dbadmin-p$dbpass-e"DROP DATABASE IF EXISTS $dbname"2>/dev/null
mysql-u$dbadmin-p$dbpass-e"DROP USER $dbname@localhost"2>/dev/null
mysql-u$dbadmin-p$dbpass-e"CREATE USER $dbname@localhost IDENTIFIED BY '$newpassword'"2>/dev/null
mysql-u$dbadmin-p$dbpass-e"GRANT ALL PRIVILEGES ON $dbname.* TO $dbname@localhost"2>/dev/null
}
Anche in questo caso abbiamo creato una password che assoceremo ad un utente chiamato come il database medesimo e che ha accesso solamente dal server locale.
Infine, per testare il tutto (questo certo non sarebbe uno standard opportuno per un vero hosting) creiamo un file index.php nel VirtualHost appena configurato e inseriamo dentro i seguenti parametri:
Se tutto è andato bene collegandoci al dominio del hosting appena registrato dovremmo veder scritto Nome_Dominio under construction e nessun avviso di Errore database.
Aggiungo anche un’ultima funzione utile per ripristinare il tutto quando si usa il parametro –fix, cancellando quindi il vhost e le relative cartelle:
1
2
3
4
5
6
7
8
9
10
call_rimuovi(){
if$ripristina
then
a2dissite"${dominio/./_}"
rm-R$www$dominio2>/dev/null
rm"${sites}${dominio/./_}.conf"
fi
}
Il codice completo, riorganizzando quanto detto prima, è questo:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
#!/bin/bash
# CONFIGURAZIONE SISTEMA
sites="/etc/apache2/sites-available/"
www="/var/www/"
# CODICE DA NON MODIFICARE
GIALLO='\033[1;33m'
ROSSO='\033[0;31m'
CELESTE='\033[1;34m'
NC='\033[0m'
TAB1='\t'
TAB2='\t\t'
aiuto=false
ripristina=false
newpassword="$(openssl rand -base64 12)"
ftppassword="$(openssl rand -base64 12)"
errore(){
echo-e"${ROSSO}ERRORE!${NC} $1. Per aiuto usare -h o --help"
Obiettivo: ampliare lo spazio su un disco di Ubuntu, aggiungendo un nuovo hard disk ed estendendo il disco con LVM
Prima di inoltrarci in questa guida sui volumi logici suggerisco di dare un’occhiata, per chi fosse ancora alle prime armi, a questo articolo sull’installazione di Ubuntu con LVM. Questo articolo prosegue sulla medesima configurazione dell’articolo citato, dove si suppone che abbiamo già installato Ubuntu predisponendolo per utilizzare l’LVM.
Quello che faremo sarà aggiungere un nuovo disco da 50 GB e poi aggiungere un altro disco da 20 GB col quale espandere il precedente.
LVM sta per logical volume manager (ovvero gestore logico dei volumi) un meccanismo attraverso il quale Linux può accorpare diversi dischi fisici in un’unico volume logico. E’ qualcosa che assomiglia, e sottolineo che si tratta solo di una somiglianza, alle configurazioni in RAID. L’idea potrebbe essere schematizzata nel modo seguente:
Il concetto di fondo è molto semplice e potremmo riassumerlo nel modo seguente: con due hard disk da 50 GB ciascuno posso creare un’unico “disco logico”, ovvero lo spazio che vede il sistema operativo, da 100 GB e posso continuare ad incrementarlo a piacere in base alle mie esigenze. Noi quindi aggiungeremo un disco 50GB e poi lo estenderemo con uno da 20GB, ottenendo uno spazio complessivo di 70GB.
Le potenzialità del LVM non si esauriscono qui, ma per quello che ci serve sapere in questo momento tanto può bastare.
In questo articolo utilizzerò ancora una volta VirtualBox, dove andrò ad aggiungere, al disco già esistente, puta caso da 50GB un secondo disco sempre da 50GB con il quale estendere la memoria a disposizione del mio sistema operativo.
Per aggiungere un nuovo disco alla mia macchina virtuale è sufficiente spostarsi, da VirtualBox, sulle Impostazioni della macchina virtuale e poi su Archiviazione.
A questo punto, come nell’immagine seguente, ci posizioniamo sul Controller SATA e clicchiamo sull’icona col disco ed il più verde e seguiamo la procedura guidata per aggiungere un secondo disco (da me chiamato DiscoUbuntuEsempio2.vdi) da 50 GB.
Fatto questo avviamo la nostra macchina virtuale come al solito. Inutile dire che se stessimo lavorando su una macchina fisica sarebbe sufficiente aggiungere fisicamente un nuovo hard disk al controller SATA.
Una volta dentro Ubuntu andiamo anzitutto a visualizzare l’elenco dei dischi fisici attualmente configurati.
1
sudo pvdisplay
Faccio notare che pv sta per phisical volume, ovvero i dischi fisici collegati all’LVM. Il risultato dovrebbe essere qualcosa di simile a questo.
Nel mio caso ho già collegato il secondo disco, ma solo un disco, quello dell’installazione, è configurato all’interno dell’LVM. Il disco nello specifico è /dev/sda5. (per essere precisi il disco è /dev/sda, mentre quello è il puntatore ad una delle “partizioni” — senza entrare troppo nel merito, che in questo momento potrebbe solo confondere le idee, possiamo dire che un singolo disco, sda in questo caso, può essere “visto” dal sistema operativo in diversi modi)
Adesso andiamo a visualizzare invece tutti i dischi collegati alla mia macchina.
1
sudo fdisk-l
Il risultato sarà esteso perché dovrebbe mostrare anche la RAM e tutti gli altri eventuali dischi e memorie collegati. Nel mio caso ad un certo punto appare:
Faccio notare che abbiamo due dischi, sda, di cui abbiamo parlato poc’anzi, e il nuovo disco sdb che abbiamo aggiunto da poco e che non è partizionato.
A questo punto creiamo una nuova partizione sul disco sdb.
1
sudo fdisk/dev/sdb
Ci verrà chiesto che cosa vogliamo fare. Le opzioni in questo momento sono:
n = nuova partizione
p = partizione primaria
1 = imposta la partizione la prima del disco
Scegliamo n per creare una nuova partizione.
Adesso ci viene chiesto se vogliamo farla primaria (p) o estesa (e). Scegliamo p per farla primaria.
Numero della partizione: 1
Alla domanda sul first sector, primo settore, digitiamo il valore suggerito di default, per me 2048.
Stesso discorso per il last sector, ovvero l’ultimo settore, scegliamo il valore suggerito di default (si può anche premere semplicemente INVIO)
Adesso abbiamo creato il nostro disco da 50GiB (ricordo che secondo il nuovo standard GiB sta per Gibibyte, che equivalgono a 1024 MiB, mentre 1GB equivale a 1000 MB, quindi 1 GiB ≠ 1 GB, inutile dire che per gli irriducibili come il sottoscritto si continuano a chiamare Gigabyte e andare di 1024 in 1024)
Continuando a trovarci su fdisk (che ci chiede un nuovo comando per proseguire o m per la guida), andiamo adesso a modificare il tipo di partizione creata digitando t e premendo INVIO.
t – modifica tipo di partizione
8e – imposta su tipo LVM
Ci verrà chiesto il tipo di partizione e digitiamo 8e.
Se digitiamo L, alla richiesta del tipo di partizione, ci verrà mostrato il seguente elenco:
Se abbiamo fatto tutto bene ci verrà mostrato il seguente messaggio di conferma:
1
Changed type of partition'Linux'to'Linux LVM'.
A questo punto è il momento di scrivere la partizione creta sul disco! Già, non l’abbiamo ancora scritta quindi nessuna di queste modifiche è ancora stata apportata. Le opzioni utili adesso sono:
p = mostra le impostazioni di partizione prima della scrittura
w = scrivi sul disco
Per scrupolo digitiamo p e verifichiamo che sia uscito qualcosa di simile.
Notiamo che sarà creato un puntatore /dev/sdb1 alla nuova partizione che ci accingiamo a creare.
Adesso premiamo w per scrivere tutte le modifiche sul nostro disco (inutile dire che ogni eventuale dato sul disco andrà perso).
Se tutto è andato bene riceveremo un messaggio di conferma come il seguente:
1
2
3
The partition table has been altered.
Calling ioctl()tore-read partition table.
Syncing disks.
Adesso dobbiamo creare il nostro volume fisico. Da terminale digitiamo:
1
sudo pvcreate/dev/sdb1
Adesso creiamo un nuovo gruppo dei volumi (in questo caso abbiamo un singolo volume) e lo andiamo a chiamare secondo-gruppo (il gruppo esistente, come visto con pvdisplay si chiama ubuntu-vg, il nome è a piacere purché sia una parola singola). Digitiamo:
1
sudo vgcreate secondo-gruppo/dev/sdb1
Adesso dobbiamo creare soltanto il volume logico e dargli un nome, per esempio spazio-web. Tra poco capirete meglio anche la scelta, intanto procediamo con:
1
sudo lvcreate-L10G-nspazio-web secondo-gruppo
Faccio notare che abbiamo creato così un volume logico di 10GB (passando la dimensione al comando -L 10G) sullo spazio complessivo disponibile di 50GB. Se avessi voluto utilizzare tutto lo spazio anziché passare il comando -L avrei dovuto scrivere
Il motivo per cui scelgo di non usare tutto lo spazio, o per essere più precisi uno dei motivi possibili, potrebbe essere il seguente: questo disco intendo dedicarlo allo spazio web in /var/www montandolo al posto della cartella esistente. Così tutti i siti web ospitati dal mio server si troveranno su un disco separato da quello principale. In questo modo posso anche controllare l’espansione di tali siti, evitando che mi saturino l’intero disco prima che io possa espanderlo. Qualora la dimensione dei siti dovesse raggiungere i 10GB, i loro utenti (che in teoria potrebbero avere degli accessi dedicati allo spazio web, per esempio mediante FTP) non potranno aggiungere altri file, mentre io potrò espandere lo spazio e adoperarmi per aggiungere nuovi hard disk.
Per chiarire questa idea immaginiamo di ospitare sul server il sito web di Mario e quello di Luigi, due persone distinte e che non si conoscono. In tutto i loro siti condividono 10GB in questo momento; immaginiamo adesso che Luigi decida di caricare sul proprio server web 3 file da 9GB. Dopo il primo upload lo spazio sarebbe saturato e Luigi non potrebbe proseguire con il successivo. Questo provocherebbe degli alert (supponendo che io li abbia configurati) all’interno della macchina e mi permetterebbe di intervenire in due modi: anzitutto controllare come mai lo spazio è cresciuto a dismisura in poco tempo, e allo stesso tempo aggiungere magari un altro paio di GB per permettere a Mario di essere comunque operativo e non sentire la saturazione dello spazio condiviso.
Concludiamo tutta l’operazione formattando il nuovo volume logico appena creato:
1
sudo mkfs-text4/dev/secondo-gruppo/spazio-web
mkfs sta letteralmente per make filesystem e il comando -t mi permette di scegliere il tipo di file system.
Controlliamo la situazione digitando di nuovo:
1
sudo pvdisplay
Dovremmo vedere qualcosa di simile a questo:
Questi sono i nostri due volumi fisici. Controlliamo adesso quelli logici digitando:
1
sudo lvdisplay
Quello che dovrebbe apparirci è la seguente schermata:
In questo caso abbiamo due gruppi distinti di volumi e tre volumi logici. I due gruppi sono ubuntu-vg e secondo-gruppo, mentre i tre volumi logici sono spazio-web, root e swap_1.
Adesso montiamo il volume logico spazio-web sulla cartella /var/www/.
Attenzione! Montando il volume su uno spazio esistente tutto il contenuto di tale spazio verrà sovrascritto, quindi prima dovremmo copiare dentro il nuovo volume il contenuto attuale. I vecchi dati comunque non andranno persi, semplicemente non saranno più visibili. Per capire bene questo passaggio facciamo la seguente serie di operazioni.
Anzitutto controlliamo il contenuto della cartella /var/www digitando:
A questo punto controlliamo nuovamente, come prima il contenuto della cartella /var/www
1
ls/var/www
Il risultato che dovrebbe presentarsi è qualcosa di simile a questo:
Notiamo che non ci sono le cartelle di prima ma solamente una cartella lost+found che si trova anche nella radice (root) del nostro sistema operativo.
Nota: la cartella lost+found esiste su ogni partizione primaria ed ha come scopo quello di collezionare eventuali file danneggiati, perduti o recuperati da fsck (per esempio). Dentro a lost+found possono finire anche file o frammenti di file a seguito di un errore di sistema (es. kernel panic) o un arresto improvviso, oppure per via di inconsistenze del sistema dovute a software o altri generi di errori. In generale quello che si trova dentro a lost+found può essere cancellato perché già eliminato dal sistema o inutile.
A questo punto, a scopo dimostrativo, creiamo dentro la cartella /var/www un file vuoto chiamato file_petar_test.txt con il seguente comando:
1
sudo touch/var/www/file_petar_test.txt
Questo lo facciamo per verificare il comportamento di mount (chiaramente non è necessario per una configurazione normale).
Adesso smontiamo la partizione in modo da copiare il contenuto originale di /var/www nella nuova partizione prima di montarla di nuovo:
1
sudo umount/var/www
Il comando umount smonta la cartella scelta. Effettuando di nuovo un ls sulla cartella /var/www ritroveremo i file precedenti:
Adesso montiamo la partizione (il volume logico) spazio-web su una cartella provvisoria che creeremo dentro a /mnt (la cartella /mnt è pensata per creare dentro le cartelle sulle quali montare volumi aggiuntivi — come è facile immaginare non c’è niente di speciale in tale cartella e il mount può essere effettuato ovunque).
Creiamo quindi la cartella provvisoria con:
1
sudo mkdir/mnt/cartella_sw
Faccio notare che il nome cartella_sw è totalmente arbitrario, l’unica condizione è che rispetti i criteri per la creazione delle cartelle in generale (sw starebbe nel mio caso per spazio-web).
A questo punto possiamo copiare il contenuto da /var/www in /mnt/cartella_sw (se controlliamo il contenuto di quest’ultima cartella noteremo il nostro file txt di prova creato in precedenza)
1
sudo cp-a/var/www/./mnt/cartella_sw/
In questo caso usiamo il comando cp per copiare, con il parametro -a gli diciamo di copiare ricorsivamente tutte le cartelle ed i file figli della cartella genitore. E’ importante scrivere /var/www/. (ovvero il percorso con incluso il punto) perché il . rappresenta il contenuto della cartella, stiamo cioè dicendo a cp che non vogliamo copiare anche /var/www, ma soltanto il suo contenuto e tutti i suoi figli.
Controllando con ls il contenuto di /mnt/cartella_sw ci accertiamo di aver copiato tutto ciò che c’era dentro a /var/www, troveremo ovviamente anche il file di prova creato precedentemente e lost+found.
A questo punto possiamo rimontare il volume logico sulla posizione /var/www (ricordiamoci di smontarlo dalla posizione corrente e cancellare la cartella /mnt/cartella_sw, lo facciamo solo per una questione di ordine). In sequenza eseguiamo quindi:
Controllando il contenuto di /var/www a questo punto dovremmo vedere qualcosa di simile a:
Inutile dire che, in linea di principio, se questa fosse stata un’operazione definitiva, avrei dovuto svuotare il contenuto di /var/www per non occupare inutilmente lo spazio sul disco primario.
A questo punto vediamo alcuni altri comandi utili.
DF, PVS e LVS
Con il comando df (disk free) controlliamo lo spazio sulle partizioni montate.
1
df-h
Il risultato dovrebbe essere simile a questo:
Notiamo che il volume logico ubuntu–vg-root (qui il formato è gruppo_volumi-volume_logico) è montato su / (la radice del sistema), mentre secondo–gruppo-spazio–web è montato su /var/www. Ci vengono mostrate anche le percentuali di utilizzo, 1% nel caso di /var/www.
Adesso vediamo le informazioni sui volumi logici utilizzando lvs.
1
sudo lvs
Faccio notare che, a differenza di df, questo necessità di permessi di root per essere eseguito.
In questo caso ci vengono mostrate le informazioni su tutti i volumi logici che abbiamo creato, comprese le loro dimensioni.
Utilizziamo adesso pvs per visualizzare i volumi fisici:
1
sudo pvs
Quello che otteniamo dovrebbe assomigliare al seguente risultato:
In questo caso vediamo i volumi fisici associati all’LVM, ed in particolare possiamo controllare lo spazio complessivo (PSize) e lo spazio libero (PFree). In particolare notiamo che su sdb1 abbiamo ancora 40GB liberi.
Quindi, riepilogando, abbiamo destinato il volume logico spazio-web, appartenente al gruppo secondo-gruppo, alla cartella /var/www. Il gruppo secondo-gruppo contiene in tutto spazio per 50GB, di cui stiamo usando solo 10GB per il volume logico spazio-web.
Estendere un volume logico
Adesso vogliamo dare altri 20GB allo spazio-web, espandendo quindi /var/www.
Per farlo ci sarà sufficiente utilizzare il comando lvextend:
1
sudo lvextend-L+20G/dev/secondo-gruppo/spazio-web
Ci verrà data conferma che l’estensione è avvenuta con successo; l’estensione può avvenire finché il gruppo dei volumi a cui appartiene il volume logico dispone di spazio libero (PFree).
Utilizziamo di nuovo df -h per verificare la situazione:
1
df-h
E dovremmo vedere qualcosa di simile a questo:
Notiamo che /var/www continua ad essere di 10GB! Questo perché oltre ad estendere il volume logico dobbiamo estendere anche il filesystem. Per farlo ci è sufficiente digitare:
1
sudo resize2fs/dev/secondo-gruppo/spazio-web
Ricontrollando con df -h vediamo che la situazione è diventata come la volevamo all’inizio:
Aggiungere volume fisico al gruppo dei volumi
Aggiungiamo adesso un disco fisico da 20GB al gruppo dei volumi chiamato secondo-gruppo, in modo che lo spazio complessivo passi da 50GB a 70GB.
Per farlo dobbiamo aggiungere naturalmente un nuovo disco, io lo faccio sulla macchina virtuale in questo caso. Verifichiamo i dischi collegati:
1
sudo fdisk-l
Il nuovo risultato dovrebbe essere simile al seguente:
Notiamo che abbiamo un disco su /dev/sdc da 20GB.
Adesso aggiungiamo il disco al gruppo di volume chiamato secondo-gruppo:
1
sudo vgextend secondo-gruppo/dev/sdc
Controlliamo i nostri volumi fisici con:
1
sudo pvs
Questo è il nuovo risultato:
Vediamo che su secondo-gruppo abbiamo ancora liberi 40G (la somma degli spazi liberi sui due dischi precedenti), quindi proviamo ad estendere spazio-web di altri 40GB, oltre ai 20GB precedentemente aggiunti. Eseguiamo i seguenti due comandi, come prima:
1
sudo lvextend-L+40G/dev/secondo-gruppo/spazio-web
Eseguendo questo comando ci viene però detto “Insufficient free space: 10240 extents needed, but only 10238 available“, ci mancano giusto 2 extents (gli extents sono l’equivalente per le LVM dei cluster per i filesystem, entrambi sono le minime unità in cui viene suddiviso lo spazio). Per evitare il problema estendiamo il volume logico su tutto lo spazio disponibile:
Notiamo come il comando assomigli al medesimo meccanismo, eccetto per il +, con il quale creiamo il volume logico su tutto lo spazio disponibile. Adesso estendiamo il filesystem.
1
sudo resize2fs/dev/secondo-gruppo/spazio-web
Prima di poterlo fare potrebbe esserci richiesto un controllo del filesystem medesimo, visto che lo abbiamo esteso poc’anzi.
1
sudo e2fsck-f/dev/secondo-gruppo/spazio-web
In questo modo eseguiamo il controllo e poi effettuiamo di nuovo resize2fs.
A questo punto eseguendo df -h notiamo che /var/www corrisponde a circa 70GB.
OK. Ho barato un po’. Arrivati a questo punto potreste in realtà notare che /var/www non è più collegata al volume logico spazio-web. Questo è successo se avete riavviato il computer per montare il secondo disco aggiuntivo. Per ottenere il risultato precedente è sufficiente montare di nuovo il volume logico, come in precedenza, oppure definire il mount in modo permanente (questo vale per qualunque disco, non solo per i volumi logici).
Montare un disco in modo permanente
Per montare il volume logico in modo permanente, ovvero che rimanga montato dopo ogni riavvio, è necessario modificare il file /etc/fstab.
1
sudo nano/etc/fstab
Per montare il disco utilizziamo la seguente sintassi:
Faccio notare che /dev/mapper/secondo–gruppo-spazio–web è il percorso che ci viene dato da df -h
Salviamo e riavviamo la macchina per verificare se va tutto bene. ATTENZIONE! Prestate moltissima attenzione alla sintassi, un qualche errore potrebbe bloccare l’avvio del sistema e costringerci ad intervenire in modalità di ripristino. La soluzione sarebbe comunque semplice, basterebbe rimuovere l’ultima riga aggiunta a fstab.
Se tutto è andato a dovere eseguendo df -h vedremo /dev/mapper/secondo–gruppo-spazio–web montata su /var/www
Gestisci Consenso Cookie
Per fornire le migliori esperienze, utilizziamo tecnologie come i cookie per memorizzare e/o accedere alle informazioni del dispositivo. Il consenso a queste tecnologie ci permetterà di elaborare dati come il comportamento di navigazione o ID unici su questo sito. Non acconsentire o ritirare il consenso può influire negativamente su alcune caratteristiche e funzioni.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.

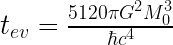
 .
. miliardi di anni, molto più dell’attuale vita dell’universo stimata attorno ai 13 miliardi di anni.
miliardi di anni, molto più dell’attuale vita dell’universo stimata attorno ai 13 miliardi di anni.