
Vogliamo realizzare un semplice programma in Python che sia in grado di riconoscere, utilizzando TensorFlow e machine learning, delle immagini di frutti.
Questo esercizio riprende i medesimi concetti già visti in: [python] Semplice esercizio su TensorFlow e il riconoscimento delle immagini nel gioco del Tris (Machine Learning)
Dato il seguente set di immagini (qui unite in una singola), vogliamo addestrare il programma a riuscire a riconoscere correttamente i frutti rappresentati:

Per farlo addestreremo il programma con altre immagini di training, suddivise rispettivamente in mele (che forse assomigliano più a dei pomodori), pere e banane:



Il risultato che vogliamo ottenere analizzando la prima immagine sarà qualcosa del genere (abbiamo tagliato l’immagine in tutte le sottoparti):

I tre numeri rappresentano la percentuale di probabilità per cui l’immagine sia, rispettivamente, una mela, una pera o una banana. Questo significa che la prima immagine è al 100% di probabilità una pera, mentre la seconda una banana ecc.
Il progetto si sviluppa in Python 3.7. Prima di procedere assicuriamoci di aver installato tutte le librerie necessarie, in particolare:
|
1 2 3 4 |
pip install Pillow pip install numpy pip install tensorflow pip install matplotlib |
A questo punto prepariamo le immagini per il training ed il test. Attraverso le immagini di training alleneremo il nostro algoritmo, mentre useremo quelle per il test per verificare l’efficacia. Sottolineo ancora una volta come questo sia un esempio semplificato al massimo, utilizzando immagini semplici per non dover produrre una grande mole di dati sia per il training che per il test.
Per preparare le immagini dobbiamo tagliare i quattro file precedentemente preparati. A tale scopo creiamo una classe per elaborare le immagini nel modo seguente (nei commenti c’è la descrizione delle singole operazioni):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
class ElaboraImmagini: # acquisiamo i dati per le immagini, con i seguenti argomenti # orig: lista che contiene il percorso alle immagini originali da tagliare # dest: cartella di destinazione nella quale salvare le immagini # n: numero di immagini in colonna # w: larghezza delle singole immagini def __init__(s, orig = [], dest = None, n = 4, w = 100): # prendiamo il percorso originale della cartella nella quale ci troviamo # ovvero dove si trova lo script di Python s.__orig_dir = os.path.dirname(os.path.realpath(__file__)) # impostiamo la variabile privata con la lista delle immagini da elaborare s.__orig = orig # creiamo la cartella di destinazione s.__dest = s.__orig_dir + "\\" + dest # se la cartella non esiste... if not os.path.exists(s.__dest): # ... allora la creiamo os.makedirs(s.__dest) # salviamo n e w in variabili private s.__n = n s.__w = w # chiamiamo l'elaborazione delle immagini s.elabora() # creiamo il metodo per elaborare le immagini def elabora(s): # per ogni file nella lista di origine for f in s.__orig: # creiamo il nome del file con il percorso assoluto nome_file = s.__orig_dir + "\\" + f # per ogni riga... for i in range(s.__n): # ... e per ogni colonna for j in range(s.__n): # ritagliamo le immagini con l'apposito metodo # al metodo verranno passate le coordinate come 4-tupla # calcolata da righe e colonne, oltre al nome del file da creare # il nome lo creiamo come: nome del file senza estensione + conteggio # quindi se stiamo tagliando banane.png avremo banane_x.png # in questo modo potremo riconoscere le immagini dai nomi dei file s.ritaglia( (j*s.__w,i*s.__w,(j+1)*s.__w,(i+1)*s.__w) , \ nome_file , \ os.path.basename(nome_file)[:-4] + "_" + str( i * s.__n + j) + ".png") # ritaglia con i seguenti argomenti: # coor: posizione left, top, right, bottom, come se fossero x e y insomma # nome_file: nome del file corrente # nome_dest: nome del file da creare def ritaglia(s, coor, nome_file, nome_dest): # apriamo il file img = Image.open(nome_file) # ritagliamolo cropped = img.crop(coor) # creiamo la posizione di salvataggio file_salvato = s.__dest + "\\" + nome_dest # salviamo cropped.save(file_salvato) |
Per elaborare i due gruppi di immagini ci sarà sufficiente chiamare:
|
1 2 |
ElaboraImmagini(["mele.png","pere.png","banane.png"],"TRAINING") ElaboraImmagini(["frutta.png"],"TEST") |
A questo punto creiamo una classe per elaborare questa base dati, nel modo seguente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
class CreaDBImmagini: # creiamo delle "costanti" giusto per codificare il tipo di output # che vogliamo ottenere passando il tipo al costruttore TEST = 0 TRAINING = 1 # qui codifichiamo la frutta MELE = 0 PERE = 1 BANANE = 2 # passiamo al costruttore due argomenti: # path: il percorso da cui leggere le immagini # tipo: il tipo di elaborazione che vogliamo fare (TEST o TRAINING) def __init__(s, path, tipo = 0): s.__path = path # lista che conterrà le immagini in byte s.__immagini = [] # lista contenente le descrizioni s.__descrizioni = [] s.__tipo = tipo s.elabora() # elaboriamo la cartella con le immagini def elabora(s): # per ciascuna immagine nella cartella for f in os.listdir(s.__path): # creiamo il percorso del file percorso_file = s.__path + "\\" + f # se il file esiste (per come è costruito il metodo non c'è # motivo per cui il file non debba esistere, in realtà # verifichiamo che eventualmente non sia una cartella) if os.path.isfile(percorso_file): # leggiamo l'immagine usando la libreria Pillow img = Image.open(percorso_file) # trasformiamo i byte dell'immagine in un array di NumPy aimg = np.asarray(img) # aggiungiamo tale array alla lista delle immagini s.__immagini.append(aimg) # se elaboriamo le immagini per il training... if s.__tipo == s.TRAINING: # preniamo il tipo del frutto dal nome # ricordiamoci che i nomi sono del tipo mela_1.png # quindi spezziamo il nome su _ e prendiamo la prima # parte frutto = f.split("_")[0] # codifichiamo il nome con il numero if frutto == "mele": desc = s.MELE if frutto == "pere": desc = s.PERE if frutto == "banane": desc = s.BANANE # aggiungiamo tale numero alla lista delle descrizioni s.__descrizioni.append(desc) # in caso di test ci accontentiamo dei meri nomi dei file if s.__tipo == s.TEST: s.__descrizioni.append(f) # metodo per restituire la lista di immagini e descrizioni # codificate come array di NumPy def get(s): return (np.array(s.__immagini), np.array(s.__descrizioni)) |
Fatto tutto questo possiamo anzitutto costruire il nostro modello, che andremo a salvare, nella stessa cartella dell’eseguibile come modello_frutta.
Per creare il modello anzitutto preleviamo le immagini con:
|
1 |
train_img, train_desc = CreaDBImmagini("TRAINING",CreaDBImmagini.TRAINING).get() |
Costruiamo poi il nostro modello:
|
1 2 3 4 5 |
modello = keras.Sequential([ keras.layers.Flatten(input_shape=(100,100,3)), keras.layers.Dense(128, activation="relu"), keras.layers.Dense(3, activation="softmax") ]) |
I tre layer servono rispettivamente per:
keras.layers.Flatten(input_shape=(100,100,3))ci permette di ridurre ad una dimensione la matrice tridimensionale delle immagini (100 righe x 100 colonne x 3 byte di colore) contenente 30.000 byte. Per farlo dobbiamo ricordarci lo shape dei dati passati in input, che provengono da una lista, contenente a sua volte una lista tridimensionale.keras.layers.Dense(128, activation="relu")applica l’algoritmo relu ai dati ottenuti dal primo layer, su 128 nodi (il numero è arbitrario, scelto per via principalmente sperimentale)keras.layers.Dense(3, activation="softmax")applichiamo l’algoritmo softmax per ridurre tutte le informazioni a 3 nodi, rappresentati i 3 dati di output che vogliamo ottenere.
Aggiungo una nota per comprendere meglio il passaggio dei layer intermedi. Il primo layer è necessario per ridurre i dati in input ad una forma univoca, mentre l’ultimo layer serve a portare in output i dati che passiamo come “descrizione”, ovvero output conosciuto, durante il training. I layer intermedi invece possono essere molteplici, e servono per manipolare i diversi aspetti dell’informazione, tentando di ridurla ad una schematizzazione ricorrente. Per capire meglio questo processo immaginiamo di voler interpretare un’immagine (non succede la medesima cosa, ma l’esempio descrive bene il concetto generale).
Se avessimo un immagine come questa di seguito, avremmo a che fare con un’enorme quantità di dettagli diversi da analizzare. Essendo l’immagine grande 1200 x 761 pixel, potremmo dire di aver bisogno di 1200×761 = 913.200 nodi per interpretare ogni informazione singolarmente, quindi potremmo decidere di utilizzare un layer con 913.200 nodi (o neuroni). Questo vorrebbe dire che diamo importanza ad OGNI singolo nodo e quindi ad OGNI singolo dettaglio dell’informazione. Laddove volessimo confrontare immagini diverse sarebbe molto complesso cercare di trovare un’affinità tra i singoli nodi e quindi un percorso che riconduca al medesimo output desiderato.

Dello stesso posto potremmo avere ad esempio la seguente immagine:

Le due immagini risulterebbero, per il computer, prese tali e quali, fondamentalmente diverse. Adesso proviamo a ridurre il dettaglio dei pixel, nel modo seguente:
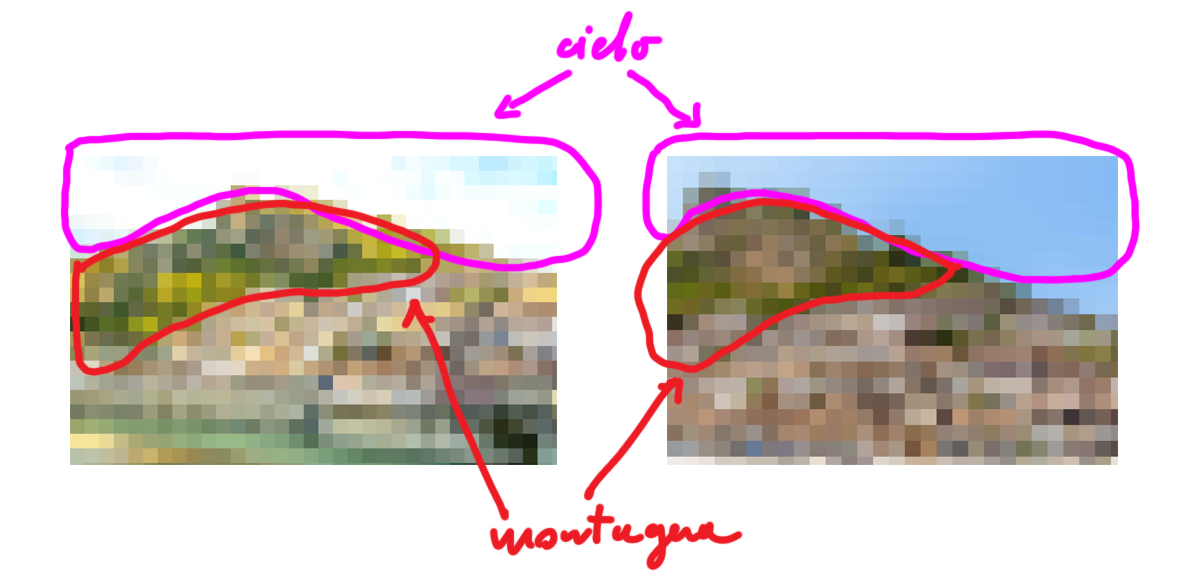
Adesso possiamo identificare, nelle immagini divese, zone analoghe associabili per forma e colore tra di loro (nonostante le differenze ancora esistenti). In questo caso abbiamo ridotto le immagini in quadrati da 36×36 pixel ciascuno, quindi in totale abbiamo ridotto il tutto a circa 700 nodi. Ovviamente si è ridotta la complessità e di conseguenza il livello di dettaglio. Potremo apprezzare meno dettagli, ma confrontare meglio i macro-elementi presenti in entrambe le immagini.
Detto tutto questo compiliamo il nostro modello:
|
1 2 3 |
modello.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) |
E infine compiliamolo e salviamolo:
|
1 2 |
modello.fit(train_img, train_desc, epochs=20) modello.save("modello_frutta") |
Per usare il modello salvato lo possiamo caricare usando:
|
1 |
modello = keras.models.load_model("modello_frutta") |
A questo punto carichiamo le immagini di TEST e mettiamo a prova il nostro modello:
|
1 |
test_img, test_desc = CreaDBImmagini("TEST",CreaDBImmagini.TEST).get() |
Adesso facciamo prevedere al modello i risultati:
|
1 |
previsione = modello.predict(test_img) |
Infine stampiamoli a video per ottenere il risultato iniziale:
|
1 2 3 |
for i, img in enumerate(test_img): previsione = modello.predict(np.array([img])) print(previsione, test_desc[i]) |
Riporto anche tutto il codice insieme:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 |
from __future__ import absolute_import, division, print_function, unicode_literals from PIL import Image import numpy as np import os import tensorflow as tf from tensorflow import keras import matplotlib.pyplot as plt class ElaboraImmagini: # acquisiamo i dati per le immagini, con i seguenti argomenti # orig: lista che contiene il percorso alle immagini originali da tagliare # dest: cartella di destinazione nella quale salvare le immagini # n: numero di immagini in colonna # w: larghezza delle singole immagini def __init__(s, orig = [], dest = None, n = 4, w = 100): # prendiamo il percorso originale della cartella nella quale ci troviamo # ovvero dove si trova lo script di Python s.__orig_dir = os.path.dirname(os.path.realpath(__file__)) # impostiamo la variabile privata con la lista delle immagini da elaborare s.__orig = orig # creiamo la cartella di destinazione s.__dest = s.__orig_dir + "\\" + dest # se la cartella non esiste... if not os.path.exists(s.__dest): # ... allora la creiamo os.makedirs(s.__dest) # salviamo n e w in variabili private s.__n = n s.__w = w # chiamiamo l'elaborazione delle immagini s.elabora() # creiamo il metodo per elaborare le immagini def elabora(s): # per ogni file nella lista di origine for f in s.__orig: # creiamo il nome del file con il percorso assoluto nome_file = s.__orig_dir + "\\" + f # per ogni riga... for i in range(s.__n): # ... e per ogni colonna for j in range(s.__n): # ritagliamo le immagini con l'apposito metodo # al metodo verranno passate le coordinate come 4-tupla # calcolata da righe e colonne, oltre al nome del file da creare # il nome lo creiamo come: nome del file senza estensione + conteggio # quindi se stiamo tagliando banane.png avremo banane_x.png # in questo modo potremo riconoscere le immagini dai nomi dei file s.ritaglia( (j*s.__w,i*s.__w,(j+1)*s.__w,(i+1)*s.__w) , \ nome_file , \ os.path.basename(nome_file)[:-4] + "_" + str( i * s.__n + j) + ".png") # ritaglia con i seguenti argomenti: # coor: posizione left, top, right, bottom, come se fossero x e y insomma # nome_file: nome del file corrente # nome_dest: nome del file da creare def ritaglia(s, coor, nome_file, nome_dest): # apriamo il file img = Image.open(nome_file) # ritagliamolo cropped = img.crop(coor) # creiamo la posizione di salvataggio file_salvato = s.__dest + "\\" + nome_dest # salviamo cropped.save(file_salvato) ElaboraImmagini(["mele.png","pere.png","banane.png"],"TRAINING") ElaboraImmagini(["frutta.png"],"TEST") class CreaDBImmagini: # creiamo delle "costanti" giusto per codificare il tipo di output # che vogliamo ottenere passando il tipo al costruttore TEST = 0 TRAINING = 1 # qui codifichiamo la frutta MELE = 0 PERE = 1 BANANE = 2 # passiamo al costruttore due argomenti: # path: il percorso da cui leggere le immagini # tipo: il tipo di elaborazione che vogliamo fare (TEST o TRAINING) def __init__(s, path, tipo = 0): s.__path = path # lista che conterrà le immagini in byte s.__immagini = [] # lista contenente le descrizioni s.__descrizioni = [] s.__tipo = tipo s.elabora() # elaboriamo la cartella con le immagini def elabora(s): # per ciascuna immagine nella cartella for f in os.listdir(s.__path): # creiamo il percorso del file percorso_file = s.__path + "\\" + f # se il file esiste (per come è costruito il metodo non c'è # motivo per cui il file non debba esistere, in realtà # verifichiamo che eventualmente non sia una cartella) if os.path.isfile(percorso_file): # leggiamo l'immagine usando la libreria Pillow img = Image.open(percorso_file) # trasformiamo i byte dell'immagine in un array di NumPy aimg = np.asarray(img) # aggiungiamo tale array alla lista delle immagini s.__immagini.append(aimg) # se elaboriamo le immagini per il training... if s.__tipo == s.TRAINING: # preniamo il tipo del frutto dal nome # ricordiamoci che i nomi sono del tipo mela_1.png # quindi spezziamo il nome su _ e prendiamo la prima # parte frutto = f.split("_")[0] # codifichiamo il nome con il numero if frutto == "mele": desc = s.MELE if frutto == "pere": desc = s.PERE if frutto == "banane": desc = s.BANANE # aggiungiamo tale numero alla lista delle descrizioni s.__descrizioni.append(desc) # in caso di test ci accontentiamo dei meri nomi dei file if s.__tipo == s.TEST: s.__descrizioni.append(f) # metodo per restituire la lista di immagini e descrizioni # codificate come array di NumPy def get(s): return (np.array(s.__immagini), np.array(s.__descrizioni)) # qui alleno il modello (ora disattivato con False) if True: train_img, train_desc = CreaDBImmagini("TRAINING",CreaDBImmagini.TRAINING).get() modello = keras.Sequential([ keras.layers.Flatten(input_shape=(100,100,3)), keras.layers.Dense(128, activation="relu"), keras.layers.Dense(3, activation="softmax") ]) modello.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"]) modello.fit(train_img, train_desc, epochs=20) modello.save("modello_frutta") # qui uso il modello if True: modello = keras.models.load_model("modello_frutta") test_img, test_desc = CreaDBImmagini("TEST",CreaDBImmagini.TEST).get() print("elenco di previsioni grezzo") previsione = modello.predict(test_img) print("elenco previsioni gestito") for i, img in enumerate(test_img): previsione = modello.predict(np.array([img])) print(previsione, test_desc[i]) |