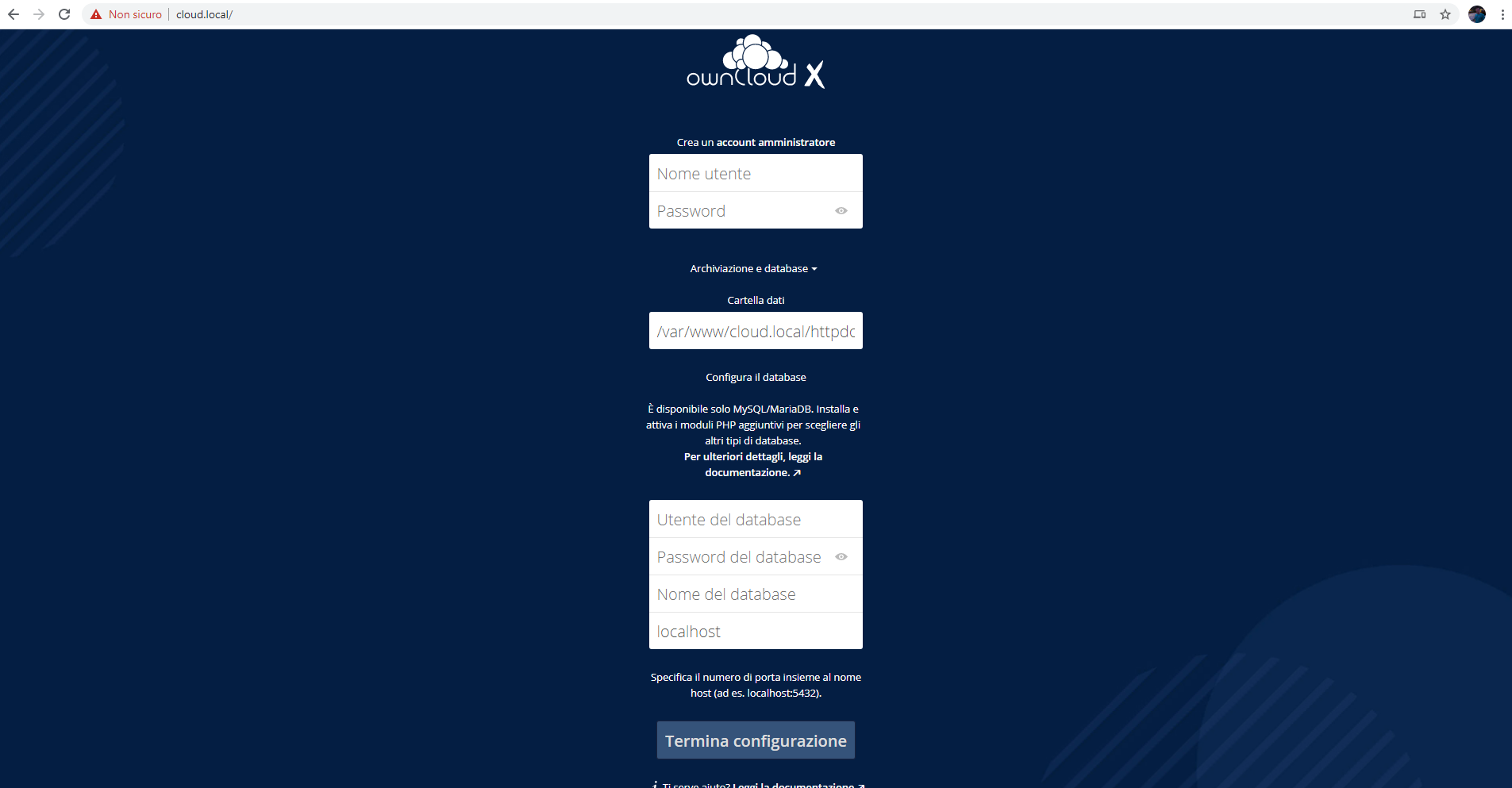
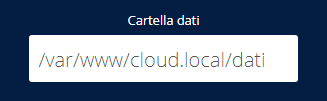
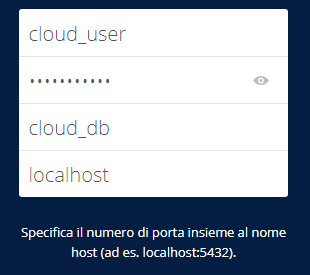
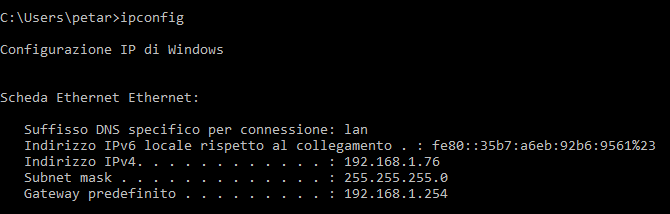
Per installare Exchange abbiamo bisogno di un Windows Server configurato come controller di dominio. Per tale configurazione rimando alla guida Configurazione Windows Server 2016 con Dominio, DNS e DHCP [per esordienti totali
1. Installazione di Exchange Server
Inseriamo il disco di installazione di Exchange Server 2016 che comparirà in Questo PC > Dispositivi e unità:
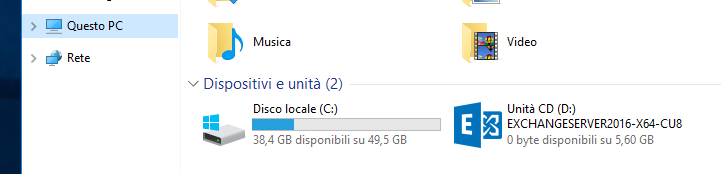
Accediamo al disco ed avviamo il Setup.
Si avvierà la richiesta di verifica degli aggiornamenti, nel mio caso li eseguirò semmai successivamente, selezionando dunque Non verificare la disponibilità di aggiornamenti adesso.
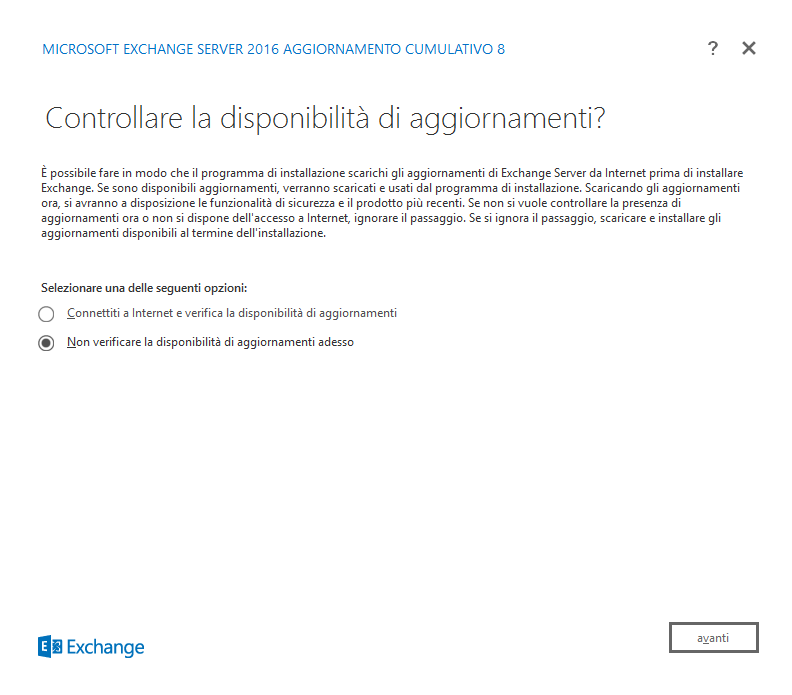
Premiamo Avanti. Si avvierà la copia dei file, attendiamo:
Nella schermata successiva scegliamo Avanti.
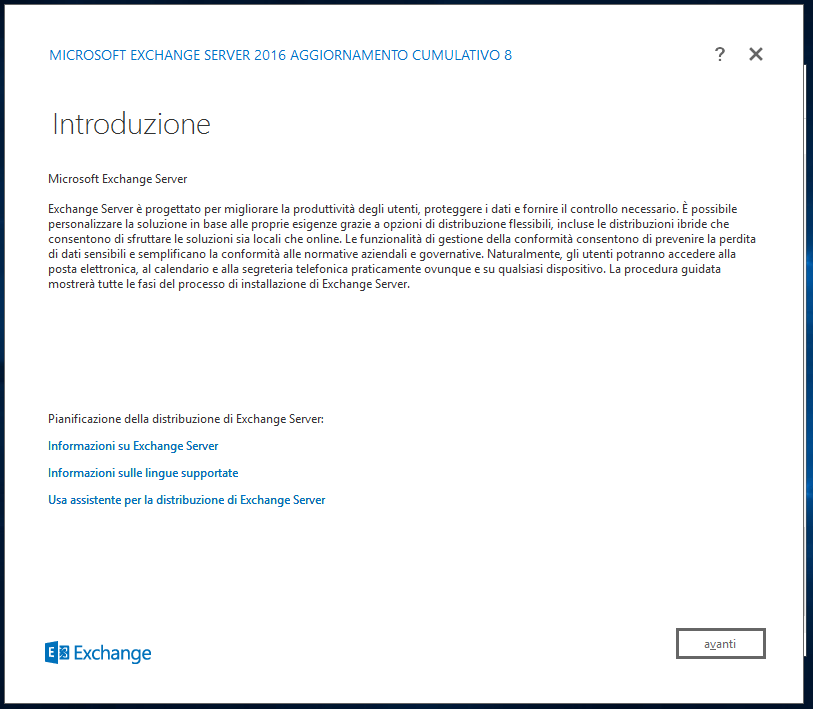
Accettiamo il Contratto di licenza.
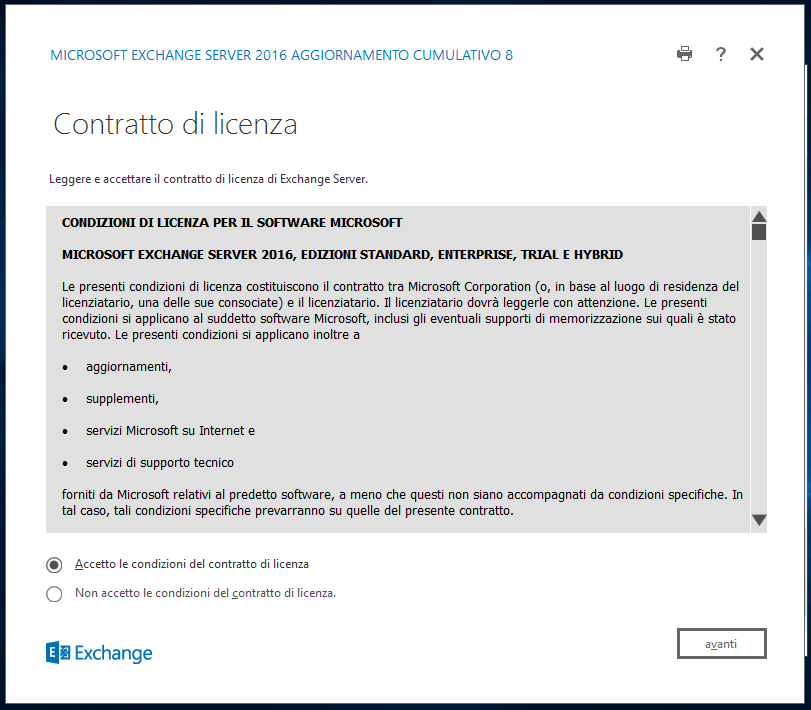
Nella schermata successiva scegliamo Usa impostazioni consigliate:
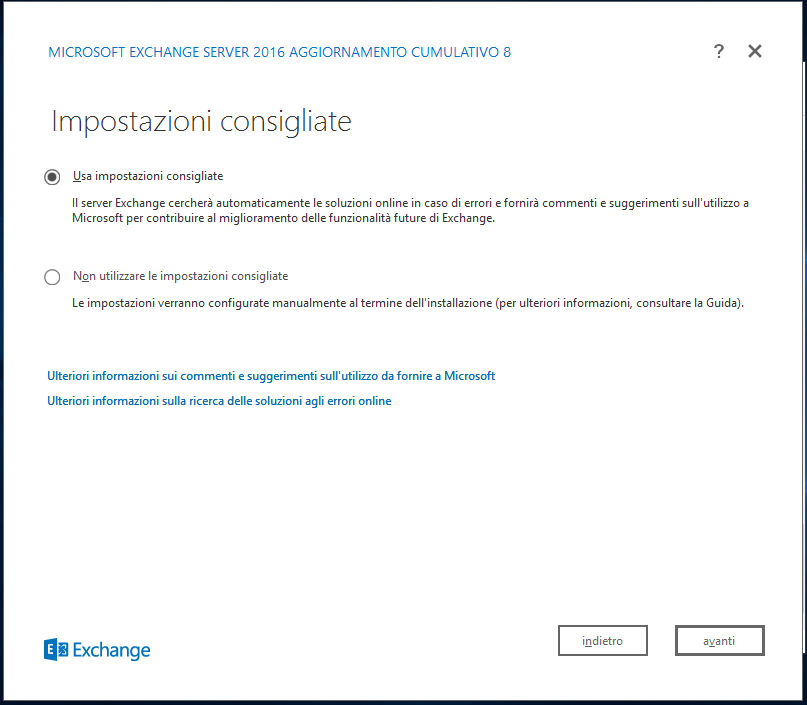
Nella Scelta del ruolo del server selezioniamo Ruolo Cassette postali e Installa automaticamente ruoli e funzionalità di Windows Server necessari per installare Exchange Server.
Premiamo di nuovo avanti.
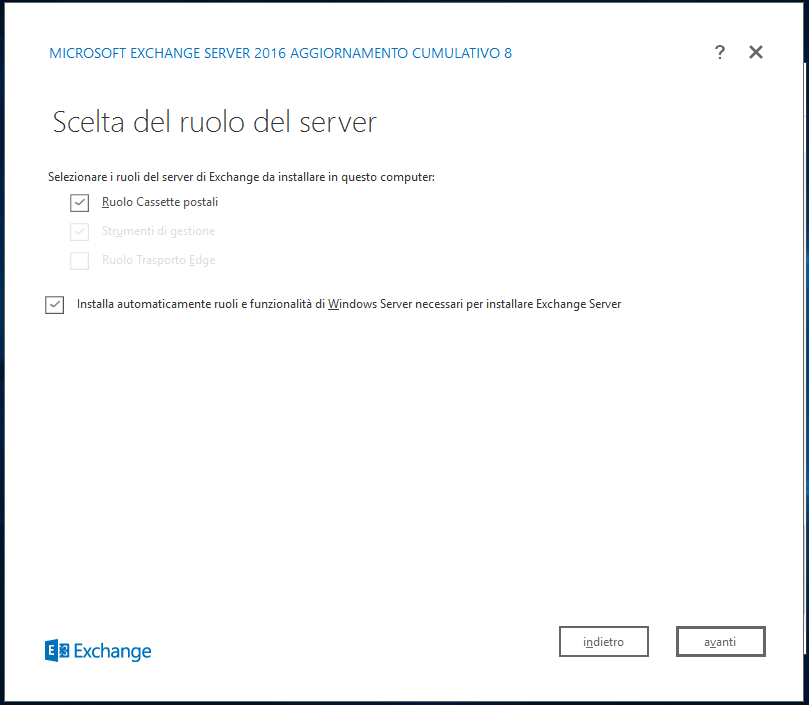
A questo punto selezioniamo la posizione di installazione di Exchange, possiamo lasciare quella predefinita e premere nuovamente Avanti.
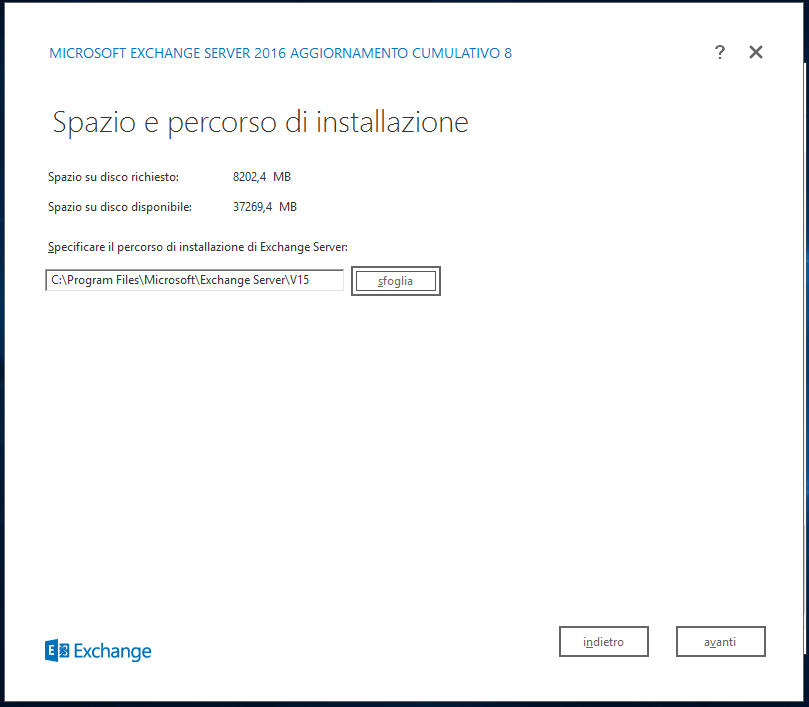
Specifichiamo un nome per la nostra organizzazione Exchange, per esempio la Torregatti Spa. Premiamo di nuovo Avanti.
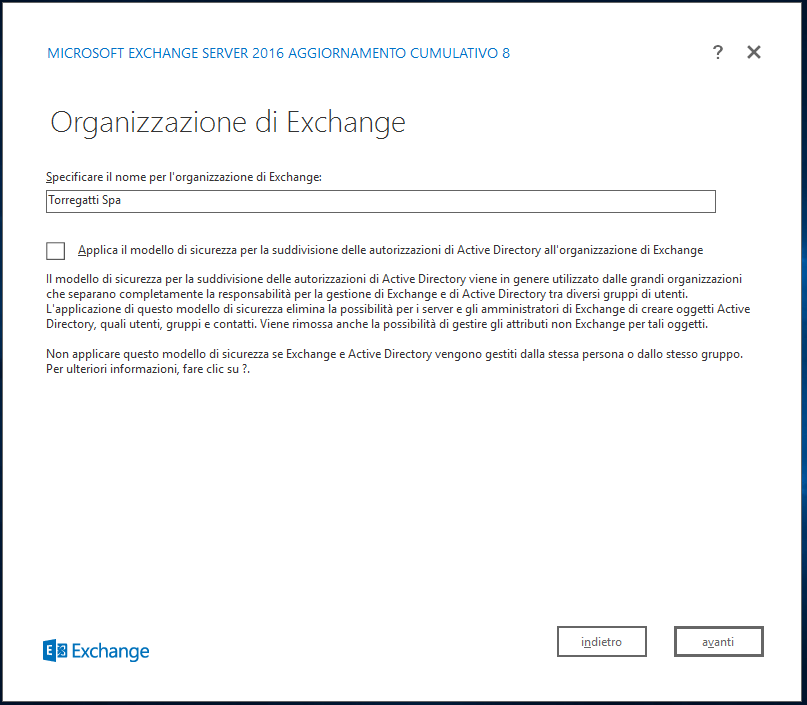
Alla richiesta se disabilitare la protezione antimalaware, diciamo di No e procediamo premendo Avanti.
Verranno avviati i controlli di conformità, attendiamo.
A questo punto è molto probabile che si presenti una serie di errori, che andranno risolti.
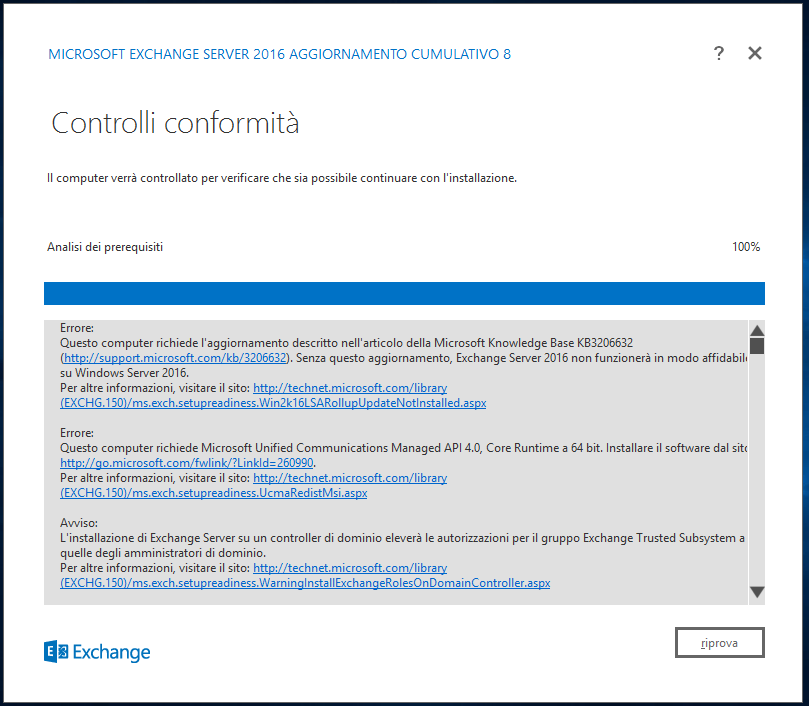
Per risolverli basterà seguire i link ed effettuare le installazioni suggerite.
Nel mio caso vengono richieste due installazioni specifiche, il cui:
Errore:
Questo computer richiede l'aggiornamento descritto nell'articolo della Microsoft Knowledge Base KB3206632 (http://support.microsoft.com/kb/3206632). Senza questo aggiornamento, Exchange Server 2016 non funzionerà in modo affidabile su Windows Server 2016.
Per altre informazioni, visitare il sito: http://technet.microsoft.com/library(EXCHG.150)/ms.exch.setupreadiness.Win2k16LSARollupUpdateNotInstalled.aspx
Errore:
Questo computer richiede Microsoft Unified Communications Managed API 4.0, Core Runtime a 64 bit. Installare il software dal sito http://go.microsoft.com/fwlink/?LinkId=260990.
Per altre informazioni, visitare il sito: http://technet.microsoft.com/library(EXCHG.150)/ms.exch.setupreadiness.UcmaRedistMsi.aspx
Alla fine dell’installazione potrebbe essere necessario riavviare. In tal caso riavviamo e poi riprendiamo l’installazione dall’inizio.
Se tutto è andato a dovere arriveremo nuovamente alla schermata precedente con solo un elenco di avvisi. A questo punto possiamo premere su Installa.
A questo punto si avvierà l’installazione vera e propria. Attendiamo.

Quando sarà tutto completato otterremo un risultato simile al seguente.
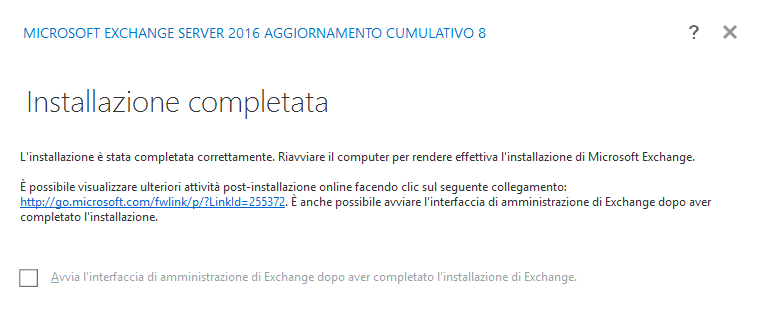
Riavviamo il sistema.
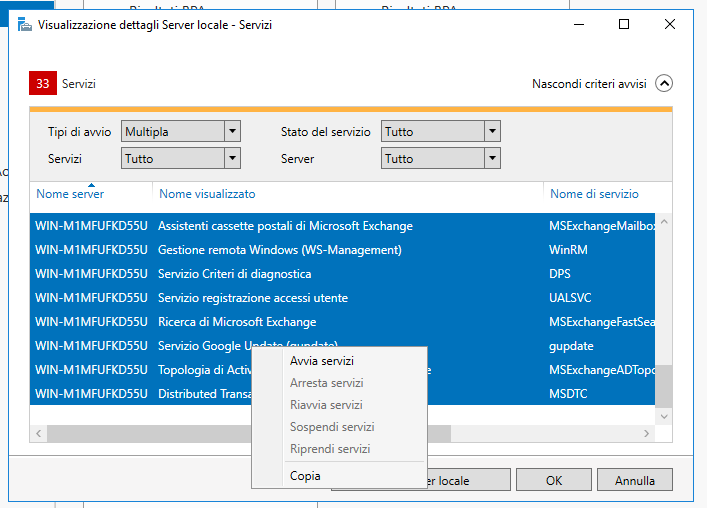
Una volta riavviato il server è probabile che dal Server Manager si vedano diversi servizi, principalmente quelli di Exchange, non avviati.
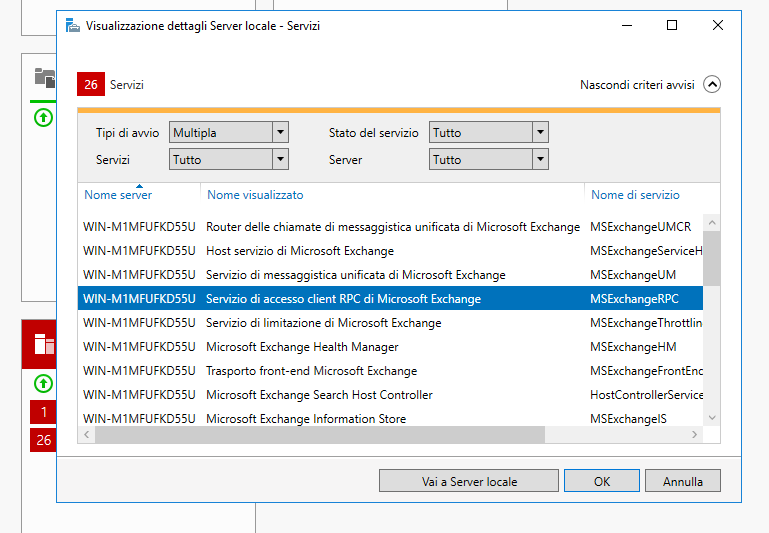
Selezioniamo i servizi (possiamo selezionarli anche tutti utilizzando SHIFT ed il mouse), clicchiamo con il destro e scegliamo Avvia Servizio.
2. Configurazioni cassette postali
Quando tutto è avviato possiamo procedere alla configurazione delle cassette postali.
Accediamo al Menù Start e cerchiamo Microsoft Exchange Server 2016 > Exchange Administrative Server

Si aprirà l’interfaccia amministrativa dentro il browser web (nel mio caso Google Chrome).
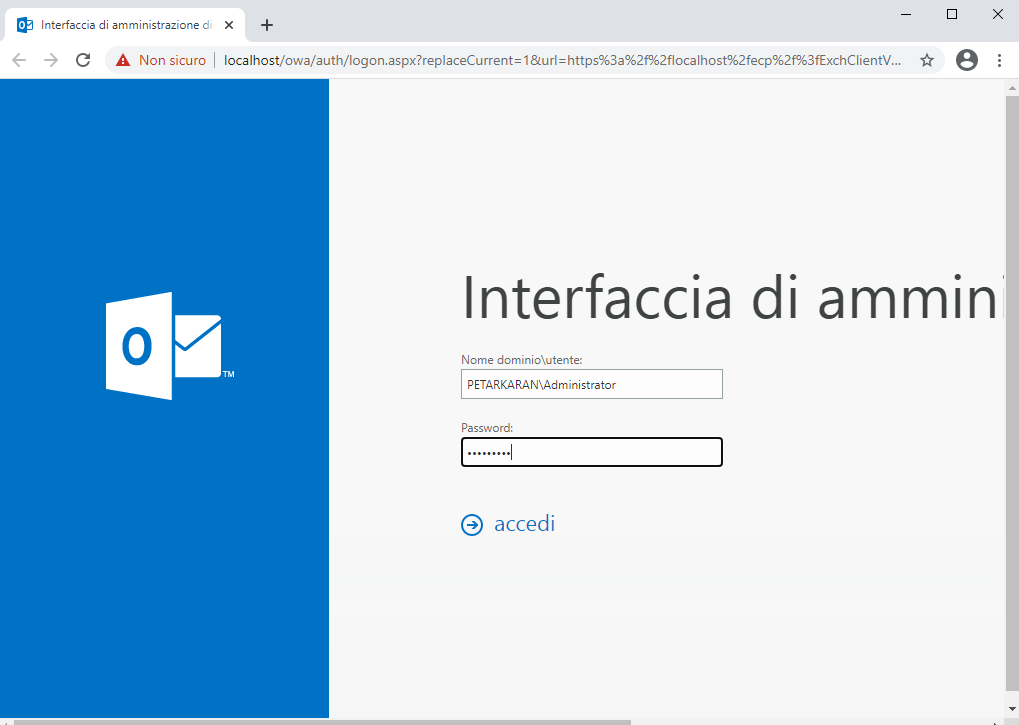
Inseriamo nome utente e password dell’amministratore del dominio e premiamo accedi.
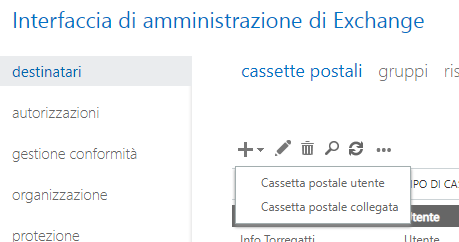
Nella scheda Destinatari > Cassette postali possiamo configurare le caselle di posta. Ogni caselle può essere associata ad un utente del dominio, oppure può essere creata una casella a se stante. Clicchiamo sul tasto più e selezioniamo Cassetta postale utente.
Ricordiamoci che il nostro dominio è petarkaran.local, quindi le caselle postali saranno del tipo nome_utente@petarkaran.local. Si aprirà quindi la finestra di configurazione della cassetta postale:
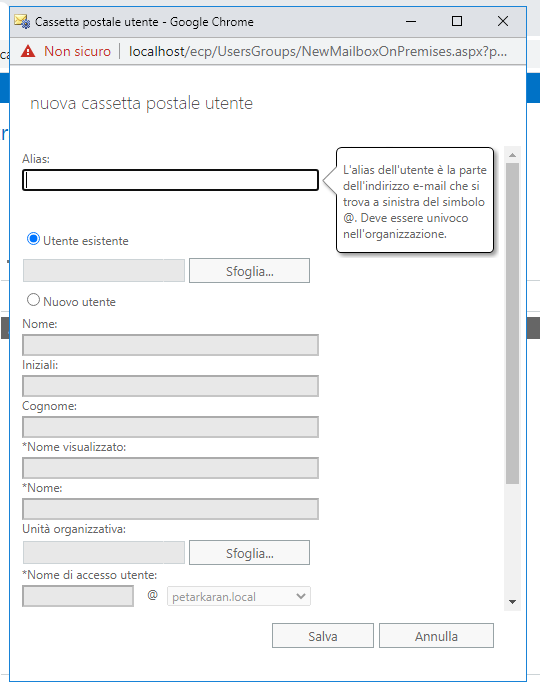
Vogliamo creare la casella luisa.neri@petarkaran.local per l’utente di dominio luisa.neri. Clicchiamo su Sfoglia… per selezionare un utente del dominio.
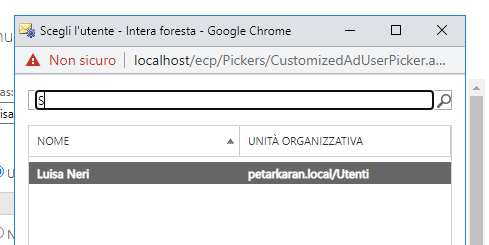
Selezioniamo l’utente desiderato e premiamo su Salva.
In questo modo abbiamo creato la cassetta postale desiderata per l’utente selezionato.
Se volessimo aggiungere un altro dominio al server di posta, per esempio un dominio esterno accettato, selezioniamo flusso di posta > domini accettati.
Vogliamo aggiungere torregatti.com. Clicchiamo sul più e compiliamo la scheda nel modo seguente:
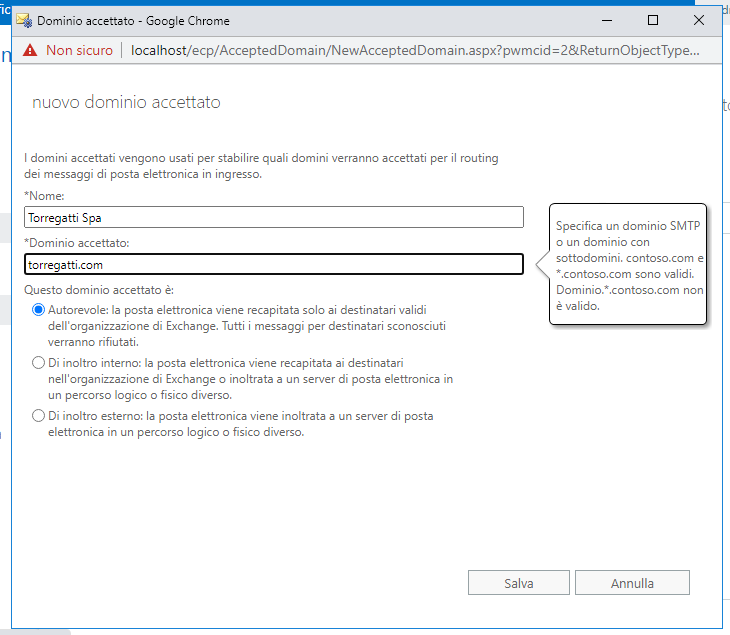
Premiamo su Salva.
Andiamo su flusso di posta > criteri degli indirizzi e-mail. Facciamo un doppio click su Default Policy. Andiamo su formato indirizzi posta elettronica.
Clicchiamo sul più. Selezioniamo il dominio appena creato, modifichiamo eventualmente il nome utente e premiamo su Salva.
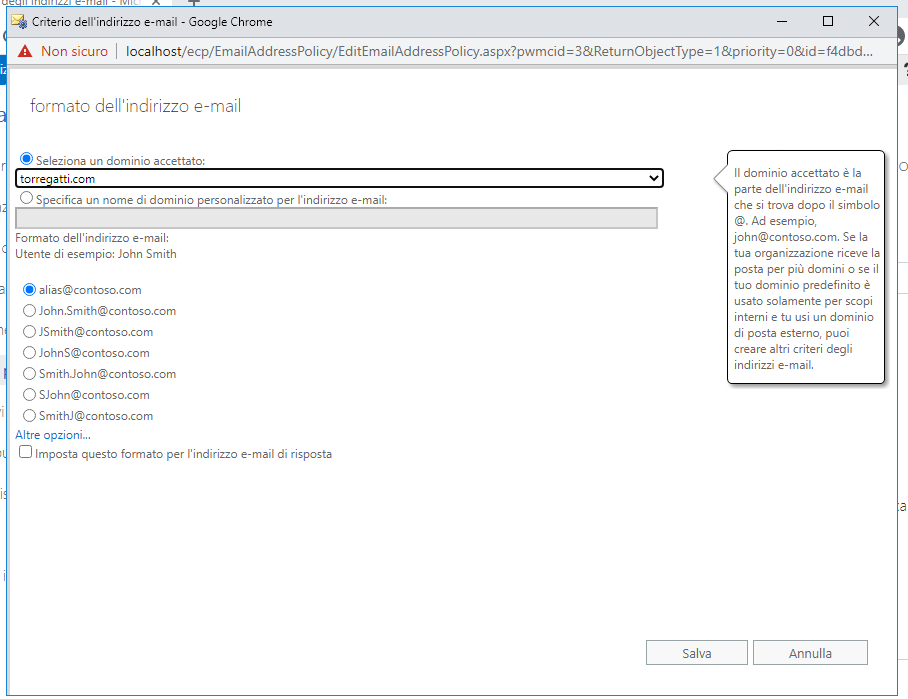
Nella schermata principale, se lo stato della policy è su Non applicato, clicchiamo su Applica, poi premiamo su Sì.
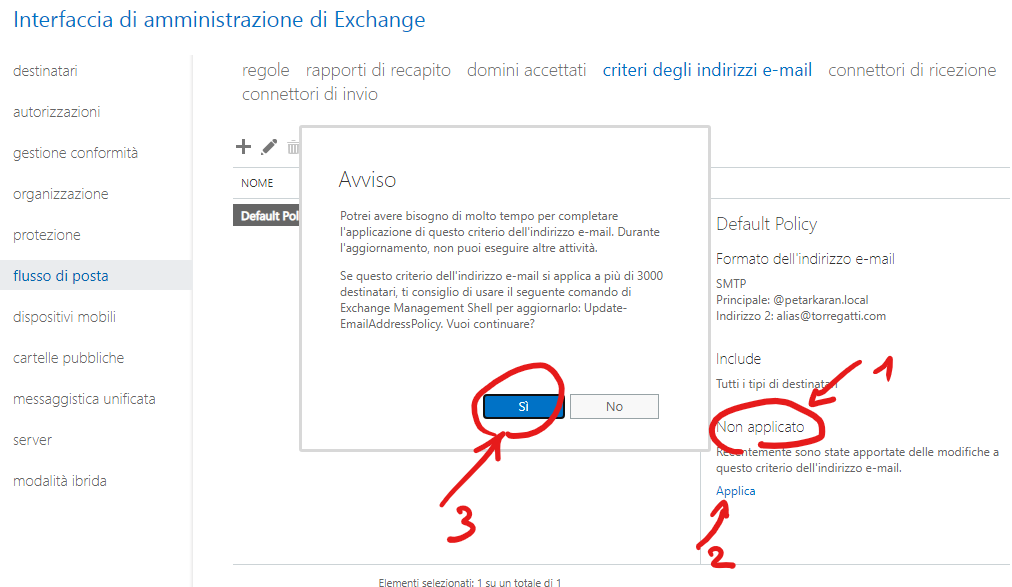
In questo modo tutti i nostri destinatari di posta potranno ricevere le email anche sull’indirizzo nome_utente@torregatti.com.