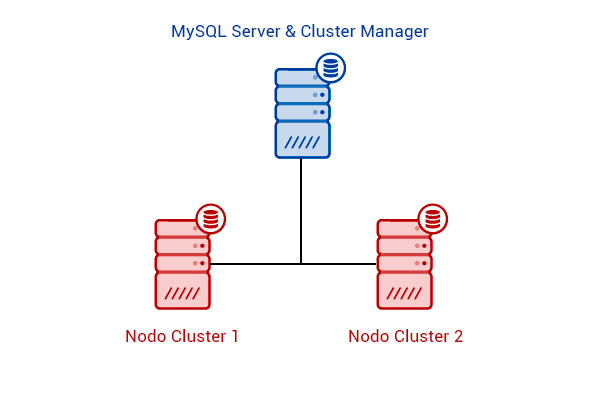
Obiettivo: creare un cluster MySQL, ovvero un server MySQL distribuito, utilizzando 3 macchine con Ubuntu, 1 per il gestore del server e 2 per i nodi
Anche questa volta, come negli altri esempi, mi avvarrò di VirtualBox, per emulare il gruppo di server. Ovviamente la procedura è valida anche su macchina fisiche oppure utilizzando un altro tipo di macchine virtuali. La struttura che andremo a creare sarà la seguente:
1. Preparazione di Ubuntu su VirtualBox
Anzitutto scarichiamo ed installiamo VirtualBox dal sito ufficiale.
Quello che voglio creare, prima di cominciare con la configurazione del cluster, sono 3 macchine con sopra Ubuntu perfettamente identiche. Sottolineo il fatto che non sia necessario che siano identiche, ma solo che su tutte e tre sia configurato correttamente il MySQL.
Cominciamo configurando la prima macchina virtuale per metterci sopra Ubuntu.
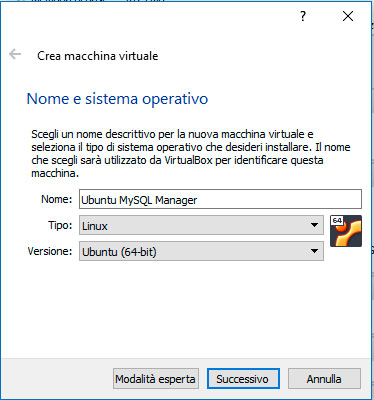
Come parametri di configurazione, nella procedura guidata, scegliamo:
- Versione: Ubuntu (64-bit)
- Dimensione memoria: 1024MB
- Disco virtuale: 10GB
- Tipo di disco: VDI
- Tipo allocazione: dinamica
Una volta creata la macchina virtuale facciamo partire ed inseriamo la ISO per l’installazione che abbiamo scaricato dal sito ufficiale di Ubuntu. Ricordo di scaricare la versione Ubuntu Server 64-bit.
Per questo esempio utilizzerò la versione 16.04.2 di Ubuntu Server.
Avviamo normalmente l’installazione, per chi non l’avesse mai fatto suggerisco di seguire la prima parte di: Installazione Ubuntu webserver pronto all’uso [per esordienti totali]
L’unica differenza è che non installeremo il server apache al momento in cui ci verrà richiesto.
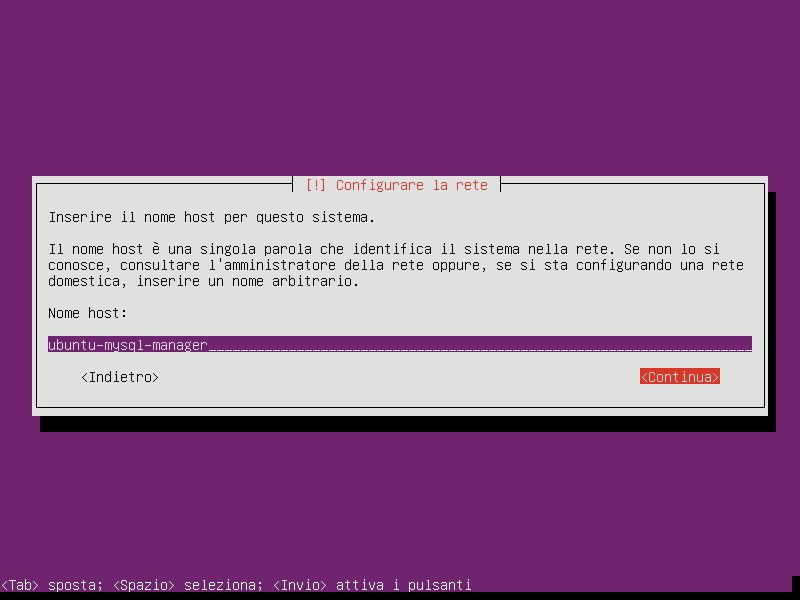
Come nome del host mettiamo ubuntu-mysql-manager (si tratta comunque di un nome a piacere):
Ad un certo punto dell’installazione ci verrà proposto quanto segue:
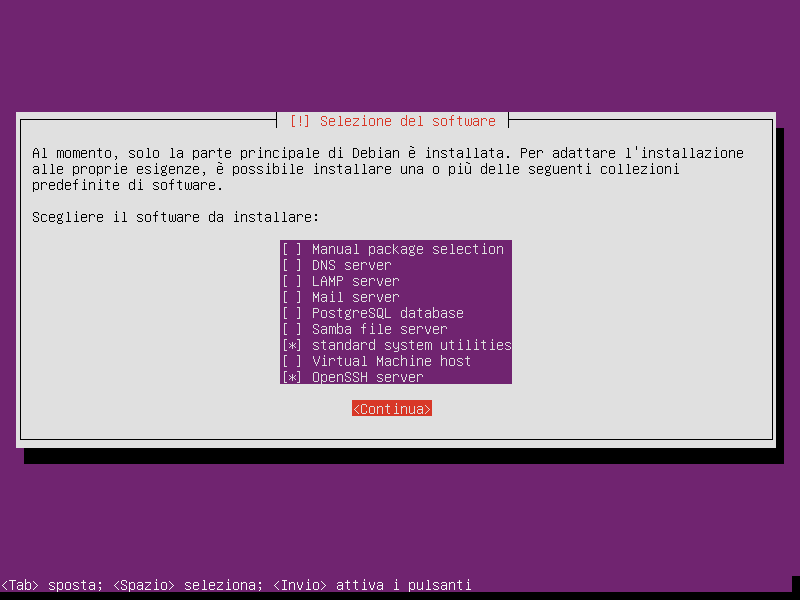
Assicuriamoci di aver selezionato solamente le voci della figura precedente, per selezionarle muoviamoci con le frecce direzionali e spuntiamo le voci premendo SPAZIO. Con la tabulazione spostiamoci su Continua e premiamo INVIO dopo aver selezionato le voci correttamente.
Una volta completata l’installazione riavviamo la macchina virtuale ed entriamo con il nome utente che abbiamo creato.
A questo punto spegniamo la macchina virtuale digitando:
Prima di procedere vogliamo creare una rete NAT interna sulla quale testare le nostre macchine. Per farlo utilizziamo le impostazioni di virtual box andando su File ⇒ Preferenze (oppure premendo CTRL+G dal panello di controllo di virtual box). A questo punto spostiamoci su Rete nel modo seguente e scegliamo di aggiungere una nuova rete.
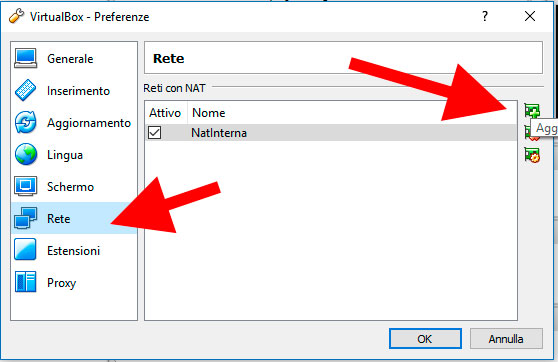
Una volta creata la nuova rete dovremmo vedere comparire una voce NatNetwork come nell’immagine seguente:
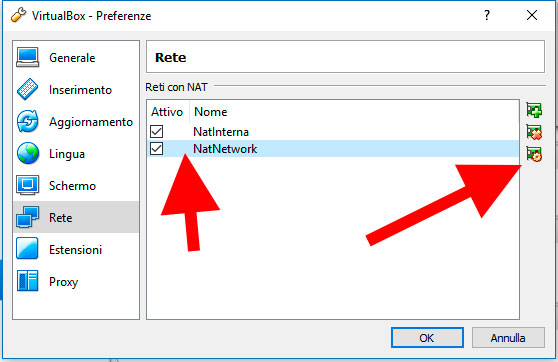
Una volta selezionata clicchiamo sul pulsante per modificarla ed impostiamola nel modo seguente:
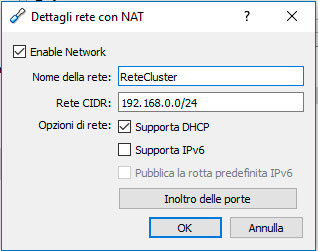
Faccio notare che l’impostazione della rete è arbitraria e a nostra scelta, quella predefinita parte sulla configurazione 10.0.2.0/24 che ho modificato nella classica rete domestica col 192.168.0.0/24 a titolo di esercizio. Questo significa che avremo a disposizione 254 host dal 192.16.0.1 al 192.16.0.254.
Diamogli OK e andiamo nelle impostazioni della macchina virtuale mettendo nella configurazione di rete la rete appena creata, in maniera seguente:
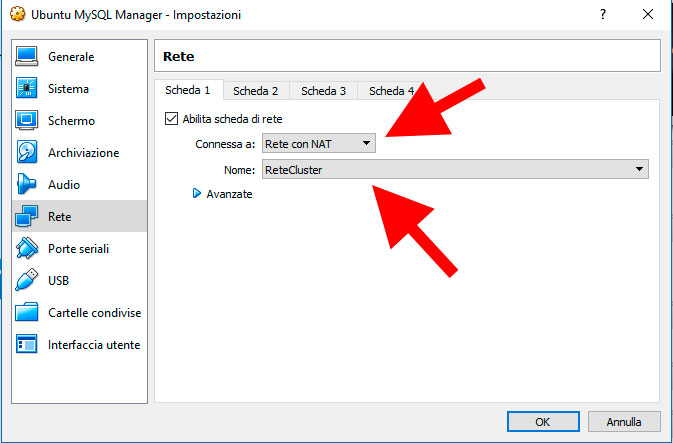
Riavviamo la macchina virtuale e colleghiamoci in SSH effettuando l’inoltro delle porte.
Per farlo, una volta partita la macchina virtuale, digitiamo:
Il risultato dovrebbe essere qualcosa di simile a questo:
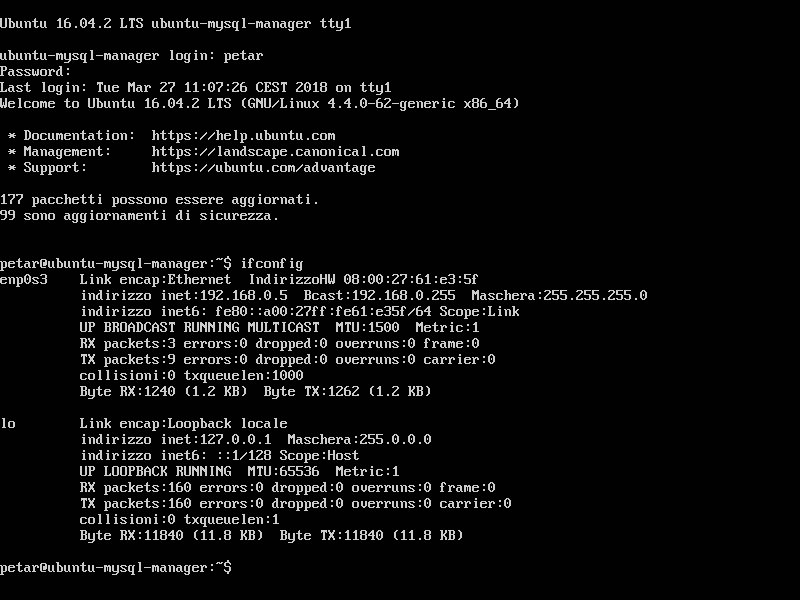
Nel mio caso noto che la macchina virtuale, di quello che diventerà il manager, si trova all’indirizzo 192.168.0.5 distribuito dal DHCP. Tornando su File ⇒ Preferenze andiamo sulla rete creata prima e apriamo le configurazioni, poi clicchiamo su Inoltro delle porte e aggiungiamo la seguente regola:
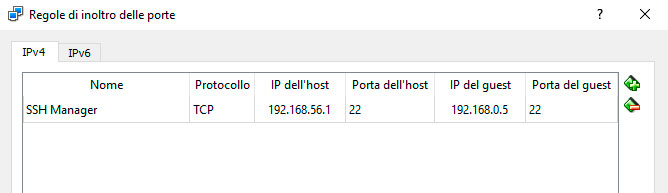
Diamo OK. Adesso possiamo collegarci in SSH dalla nostra macchina host (detto banalmente: dal nostro PC che ospita le macchine virtuali) usando l’indirizzo 192.168.56.1 porta 22.
Fatta questa bella impostazione possiamo passare al passaggio successivo.
2. Installazione MySQL sul primo Nodo
Anzitutto installiamo il cluster su tutti i nostri nodi, nello specifico lo installiamo sulla macchina appena creata che poi duplicheremo opportunamente. Per l’installazione possiamo seguire i passaggi indicati sul sito ufficiale, oppure scaricare dalla pagina ufficiale i file .deb necessari.
Io utilizzerò la repository APT, ma prima di cominciare installiamo le dipendenze necessarie al funzionamento del cluster:
|
|
sudo apt-get install python-paramiko libclass-methodmaker-perl libaio1 |
A questo punto dobbiamo installare la MySQL APT Repository sul nostro sistema. Per farlo ci è sufficiente scaricare il file di installazione dal sito ufficiale andando qui. Nello specifico digitiamo:
|
|
wget https://dev.mysql.com/get/mysql-apt-config_0.8.9-1_all.deb |
Una volta scaricato il file procediamo all’installazione:
|
|
sudo dpkg -i mysql-apt-config_0.8.9-1_all.deb |
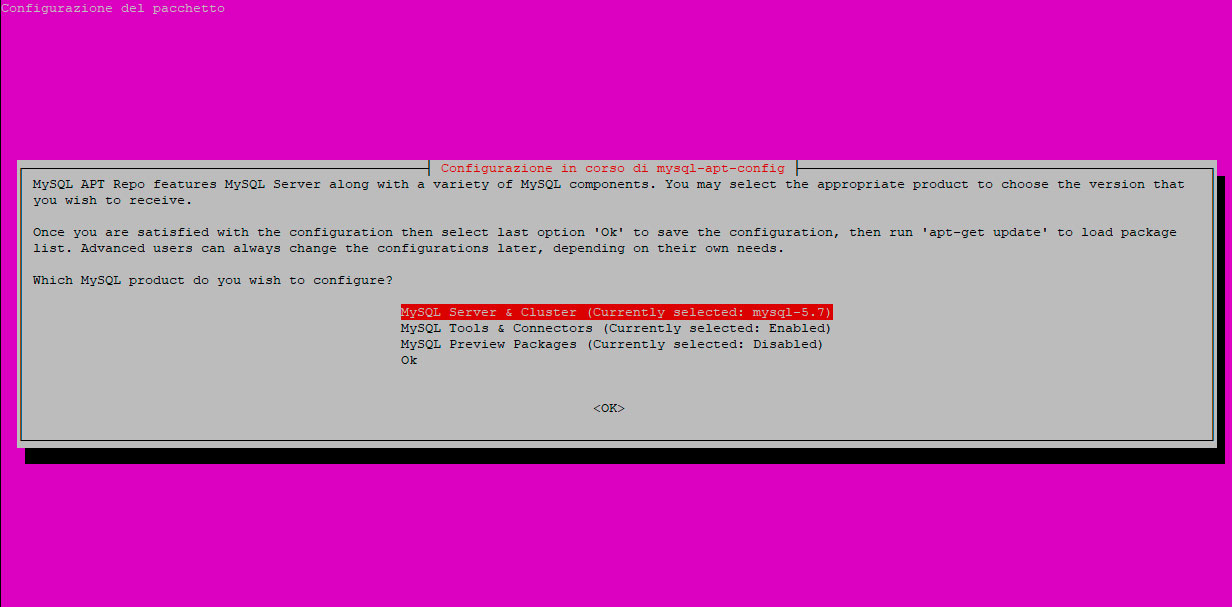
A questo punto ci verrà chiesto che cosa intendiamo configurare e scegliamo la voce MySQL Server & Cluster:
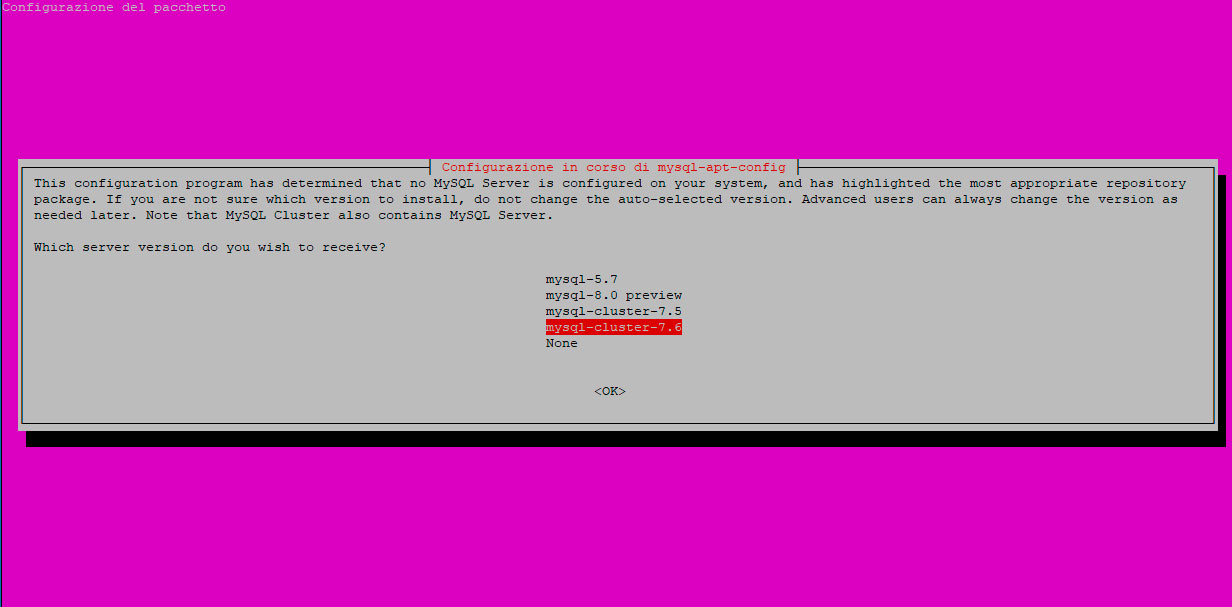
Ci verrà chiesta la versione che intendiamo installare e selezioniamo mysql-cluster-7.6:
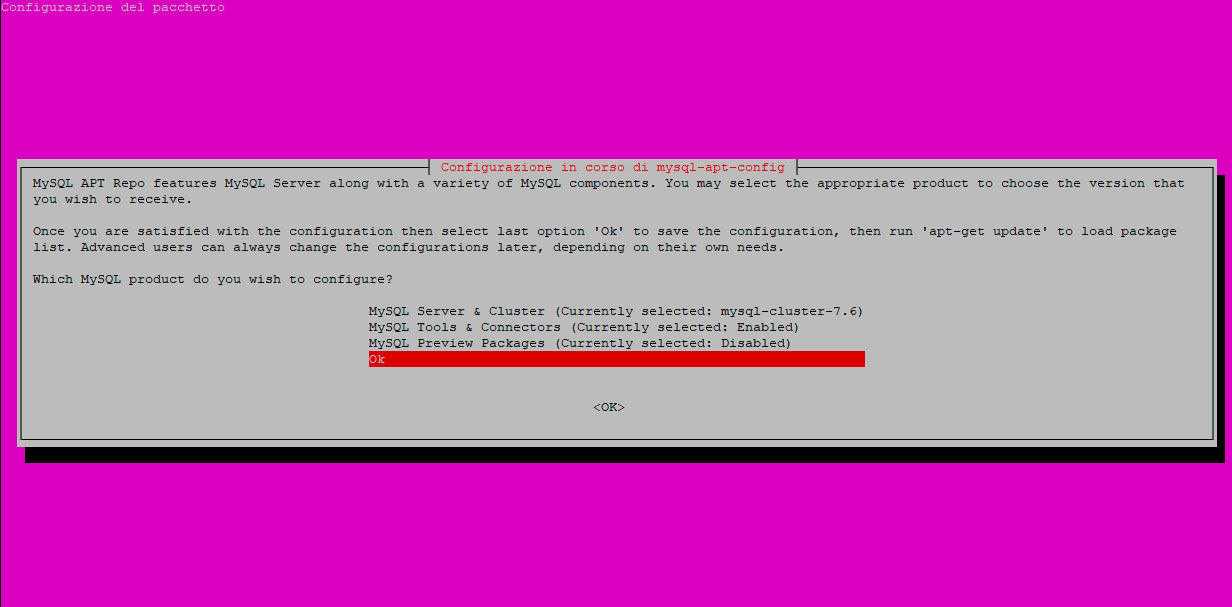
A questo punto torniamo alla schermata precedente e selezioniamo OK:
A questo punto non ci rimane che installare il componente base per tutti i nodi digitando:
|
|
sudo apt-get update sudo apt-get install mysql-cluster-community-server |
L’update ci serve per aggiornare la repository dopo le recenti modifiche, altrimenti è probabile che sia impossibile trovare mysql-cluster-community-server.
Ad un certo punto ci verrà chiesto di impostare una password per l’utente root del database, impostiamo una password e segniamocela da qualche parte. Ricordo che l’utente root non è quello del sistema, ma del database.
A questo punto abbiamo preparato un nodo.
Replicheremo questo nodo per altre due volte, designando un singolo nodo come manager del cluster.
3. Replica dei nodi
Per replicare i nodi possiamo decidere di creare un’immagine del nostro sistema che reinstalleremo a piacere, oppure, visto che stiamo usando VirtualBox di duplicare le macchine virtuali. Quindi spegniamo la nostra macchina e creiamone una copia.
Per farlo ci è sufficiente cliccare sulla macchina virtuale e selezionare Clona…
A questo punto ci verrà mostrata una schermata delle opzioni da configurare nel modo seguente:
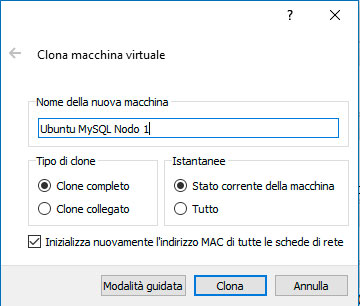
Spuntiamo l’inizializzazione di un nuovo indirizzo MAC (visto che vogliamo usare le macchine insieme) e diamo un nome alla nuova macchina, nel mio caso Ubuntu MySQL Nodo 1.
Ripetiamo la medesima operazione per creare un Ubuntu MySQL Nodo 2.
A questo punto sistemiamo la nostra rete per poter accedere alle macchine virtuali. Per farlo assegniamo a tutte le macchine un indirizzo IP statico, modifichiamo opportunamente i nomi e configuriamo il file hosts in modo tale che possano vedersi le une con le altre. La configurazione finale sarà così:
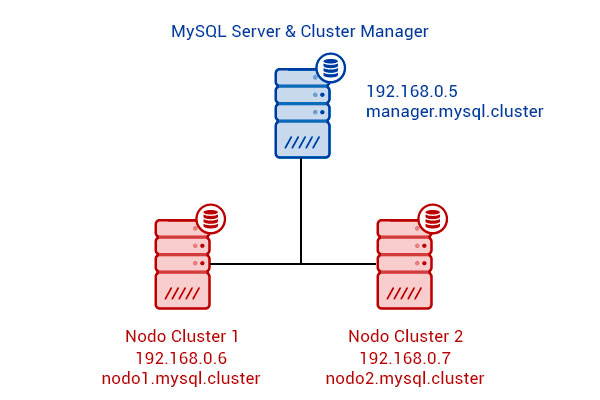
Cominciamo con Ubuntu MySQL Manager.
Usando ifconfig verifichiamo che la nostra macchina si trovi all’indirizzo 192.168.0.5. Scopriamo il nostro gateway digitando:
Il risultato dovrebbe assomigliare a qualcosa di simile:
|
|
Tabella di routing IP del kernel Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.0.1 0.0.0.0 UG 0 0 0 enp0s3 192.168.0.0 0.0.0.0 255.255.255.0 U 0 0 0 enp0s3 |
Il gateway è quindi 192.168.0.1, ricordiamoci che la nostra rete è stata impostata con netmask /24 ovvero 255.255.255.0
Impostiamo quindi tale indirizzo come indirizzo statico, usando le informazioni che abbiamo raccolto.
|
|
sudo nano /etc/network/interfaces |
Modifichiamo il file interfaces affinché abbia il seguente contenuto:
|
|
# This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback # The primary network interface auto enp0s3 iface enp0s3 inet static address 192.168.0.5 netmask 255.255.255.0 gateway 192.168.0.1 dns-nameservers 8.8.8.8 |
Faccio notare che per il DNS utilizziamo il DNS di Google all’indirizzo 8.8.8.8.
A questo punto riavviamo la scheda di rete digitando:
|
|
sudo ifdown enp0s3 && sudo ifup enp0s3 |
Faccio notare che la nostra interfaccia di rete è enp0s3, mentre in una classica configurazione fisica probabilmente sarebbe eth1.
Fatto questo modifichiamo il file hosts inserendo gli host stabiliti all’inizio:
|
|
192.168.0.5 manager.mysql.cluster 192.168.0.6 nodo1.mysql.cluster 192.168.0.7 nodo2.mysql.cluster |
Il file alla fine dovrebbe risultare qualcosa di simile a questo:
|
|
127.0.0.1 localhost 127.0.1.1 ubuntu-mysql-manager 192.168.0.5 manager.mysql.cluster 192.168.0.6 nodo1.mysql.cluster 192.168.0.7 nodo2.mysql.cluster # The following lines are desirable for IPv6 capable hosts ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters |
Salviamo il tutto, spegniamo la macchina (onde evitare conflitti, dal momento che sono tutte duplicate) e spostiamoci sul prossimo nodo.
Configurazione Ubuntu MySQL Nodo 1
Prima di procedere soffermiamoci un attimo a configurare le porte per l’inoltro sulla scheda di virtual box, ottenendo una configurazione simile a questa:
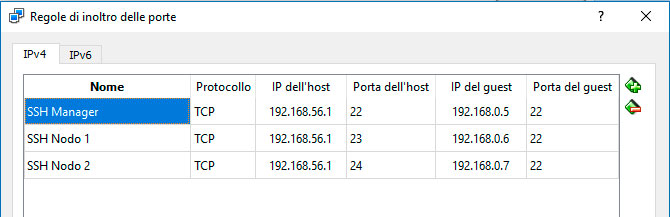
In questo modo collegandoci su porte diverse dell’interfaccia esterna potremo accedere, mediante SSH, alle specifiche macchine virtuali.
Una volta avviato il secondo nodo è molto probabile, essendo la prima macchina sull’indirizzo 192.168.0.5, che questo si trovi sull’indirizzo 192.168.0.6. Se facciamo tutto in questo ordine ci risparmiamo qualche piccolo lavoretto extra nella riassegnazione degli indirizzi. Colleghiamoci quindi al nostro nodo 1 (se usate Putty potete collegarvi al 192.168.56.1:23) e modifichiamo la scheda di rete con l’indirizzo statico, come abbiamo fatto prima.
|
|
sudo nano /etc/network/interfaces |
Il risultato sarà simile a questo:
|
|
# This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback # The primary network interface auto enp0s3 iface enp0s3 inet static address 192.168.0.6 netmask 255.255.255.0 gateway 192.168.0.1 dns-nameservers 8.8.8.8 |
Modifichiamo il file hosts:
Aggiungiamo le righe di prima:
|
|
192.168.0.5 manager.mysql.cluster 192.168.0.6 nodo1.mysql.cluster 192.168.0.7 nodo2.mysql.cluster |
E notiamo che abbiamo ancora ubuntu-mysql-manager come riferimento interno. Rinominiamolo in ubuntu-mysql-nodo1. Il file hosts alla fine risulterà così:
|
|
127.0.0.1 localhost 127.0.1.1 ubuntu-mysql-nodo1 192.168.0.5 manager.mysql.cluster 192.168.0.6 nodo1.mysql.cluster 192.168.0.7 nodo2.mysql.cluster # The following lines are desirable for IPv6 capable hosts ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters |
Infine modifichiamo il hostname digitando:
Anche qui dentro sostituiamo il nome di poco fa con quello nuovo, ovvero ubuntu-mysql-nodo1.
Fatto tutto questo spegniamo la macchina e passiamo al secondo nodo.
Configurazione Ubuntu MySQL Nodo 2
A questo punto dovrebbe essere tutto semplice, basta replicare quanto fatto per il nodo 1.
Il file /etc/network/interfaces avrà quindi il seguente aspetto:
|
|
# This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback # The primary network interface auto enp0s3 iface enp0s3 inet static address 192.168.0.7 netmask 255.255.255.0 gateway 192.168.0.1 dns-nameservers 8.8.8.8 |
Il file /etc/hosts apparirà così:
|
|
127.0.0.1 localhost 127.0.1.1 ubuntu-mysql-nodo2 192.168.0.5 manager.mysql.cluster 192.168.0.6 nodo1.mysql.cluster 192.168.0.7 nodo2.mysql.cluster # The following lines are desirable for IPv6 capable hosts ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters |
Mentre il file /etc/hostname conterrà una sola riga:
A questo punto anche il secondo nodo è pronto e possiamo spegnere la macchina.
4. Installazione del MySQL Cluster Manager
Adesso riavviamo il nostro cluster manager e avviamo l’installazione del software manager:
|
|
sudo apt-get install mysql-cluster-community-management-server |
Una volta installato andiamo a creare la seguente cartella nella quale metteremo il file di configurazione:
|
|
sudo mkdir /var/lib/mysql-cluster |
Creiamo dentro un file chiamato config.ini:
|
|
sudo nano /var/lib/mysql-cluster/config.ini |
A questo punto procediamo alla configurazione nel modo seguente:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
[ndbd default] # opzioni che interesseranno tutti i nodi NoOfReplicas=2 # numero di repliche DataMemory=80M # quantità di memoria allocata per l'archivazione dei dati IndexMemory=18M # quantità di memoria allocata per l'indicizzazione dei dati ServerPort=2202 # porta di connessione, non è necessario impostarla, la metto qui a titolo di esercizio [ndb_mgmd] # configurazione del manager HostName=manager.mysql.cluster # oppure ci possiamo mettere l'indirizzo ip, nel nostro caso sarebbe 192.168.0.5 DataDir=/var/lib/mysql-cluster # cartella che conterrà i file LOG dei nodi [ndbd] # opzioni nodo 1 HostName=nodo1.mysql.cluster NodeId=2 DataDir=/usr/local/mysql/data [ndbd] # opzioni nodo 2 HostName=nodo2.mysql.cluster NodeId=3 DataDir=/usr/local/mysql/data [mysqld] #questa è la posizione dove si troverà il daemon del MySQL, il processo in esecuzione insomma HostName=manager.mysql.cluster |
Ho inserito i commenti ai singoli parametri nel file stesso in modo da rendere più agevole la consultazione. I parametri in cima non sono di per se necessari, ma li mettiamo a scopo didattico per tenere presente che eventualmente li potremo modificare in base alle nostre esigenze.
Per finire installiamo il mysql-server, dal momento che abbiamo detto che il daemon del MySQL si troverà sulla medesima macchina del menager. Digitiamo:
|
|
sudo apt-get install mysql-server |
Fatto.
5. Configurazione dei nodi
Adesso avviamo i nostri due nodi e configuriamoli nella maniera seguente (io qui configurerò il primo nodo, la stessa cosa va fatta sul secondo).
Anzitutto installiamo il programma per ciascun nodo digitando:
|
|
sudo apt-get install mysql-cluster-community-data-node |
Quindi digitiamo:
|
|
sudo nano /etc/mysql/my.cnf |
Dentro al file scriviamo:
|
|
[mysqld] ndbcluster [mysql_cluster] ndb-connectstring=manager.mysql.cluster |
In questo modo collegheremo il nodo al cluster, demandando la gestione del servizio al cluster medesimo.
6. Avvio del cluster
Ora che abbiamo configurato sia il manager che gli altri nodi possiamo procedere all’avvio del nostro cluster.
Spostiamoci sul manager e digitiamo:
|
|
sudo ndb_mgmd -f /var/lib/mysql-cluster/config.ini |
Questo avvierà il cluster sul manager importando il file di configurazione. Affinché si avvii automaticamente ad ogni riavvio modifichiamo il file di avvio nel seguente modo.
Anzitutto abilitiamo i servizi locali digitando:
|
|
sudo systemctl enable rc-local.service |
E modifichiamo il file:
Inserendo, prima di exit 0, il precedente comando (questo sarà l’aspetto complessivo del file):
|
|
#!/bin/sh -e # # rc.local # # This script is executed at the end of each multiuser runlevel. # Make sure that the script will "exit 0" on success or any other # value on error. # # In order to enable or disable this script just change the execution # bits. # # By default this script does nothing. ndb_mgmd -f /var/lib/mysql-cluster/config.ini exit 0 |
Adesso spostiamoci sui singoli nodi e per ciascun nodo digitiamo:
|
|
sudo mkdir -p /usr/local/mysql/data |
In questo modo creeremo la cartella per l’allocazione dei dati necessaria al nodo (con il comando -p diciamo ad mkdir di creare l’intero percorso).
Dopodiché avviamo il nodo digitando:
Affinché anche tutto ciò parta all’avvio digitiamo:
|
|
sudo systemctl enable rc-local.service |
E poi ancora:
Modifichiamo il file affinché appaia in questo modo:
|
|
#!/bin/sh -e # # rc.local # # This script is executed at the end of each multiuser runlevel. # Make sure that the script will "exit 0" on success or any other # value on error. # # In order to enable or disable this script just change the execution # bits. # # By default this script does nothing. ndbd exit 0 |
Riavviamo il tutto.
7. Verifichiamo il funzionamento del cluster
A questo punto possiamo verificare il funzionamento del cluster spostandoci sul nostro manager e digitando:
Entrando nel terminale del ndb_ngm digitiamo:
Quello che dovremmo vedere sarà qualcosa di simile a questo:
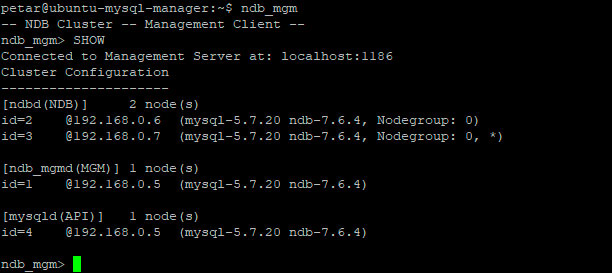
Se tutto è andato bene questo sarà il risultato. Qualora uno dei nodi non fosse raggiungibile, oppure non fosse possibile collegarsi al daemon ci verrebbe segnalato esplicitamente.
Per uscire dal manager è sufficiente digitare exit e premere invio.
Come ultima operazione proviamo a creare una tabella sul nostro cluster.
8. Creiamo una tabella sul cluster
Accediamo anzitutto al mysql digitando nel manager:
Questo ci permetterà di accedere con l’utente root del database e ci verrà chiesta la password a schermo.
Anche qui possiamo fare una seconda verifica di quello che ci è già noto:

Infatti se tutto è andato bene ci verrà dato il benvenuto con la versione del MySQL Cluster Community Server.
A questo punto creiamo il nostro database di prova digitando:
|
|
CREATE DATABASE cluster_test; |
Inseriamo nel database cluster_test la nostra tabella di prova:
|
|
USE cluster_test; CREATE TABLE cluster_test (nome VARCHAR(20), cognome VARCHAR(20)) ENGINE=ndbcluster; |
ATTENZIONE! E’ molto importante che l’engine sia impostato su ndbcluster, affinché la tabella lavori e sia distribuita sul cluster.
Inseriamo dei valori di prova:
|
|
INSERT INTO cluster_test (nome,cognome) VALUES('mario','rossi'); |
Adesso proviamo ad interrogare la tabella digitando:
|
|
SELECT * FROM cluster_test; |
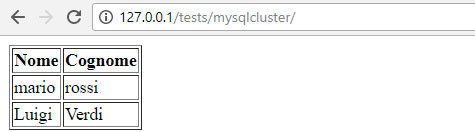
Il risultato dovrebbe essere questo:
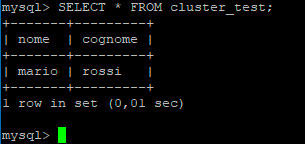
Fatto, abbiamo il nostro cluster perfettamente funzionante e pronto all’uso.