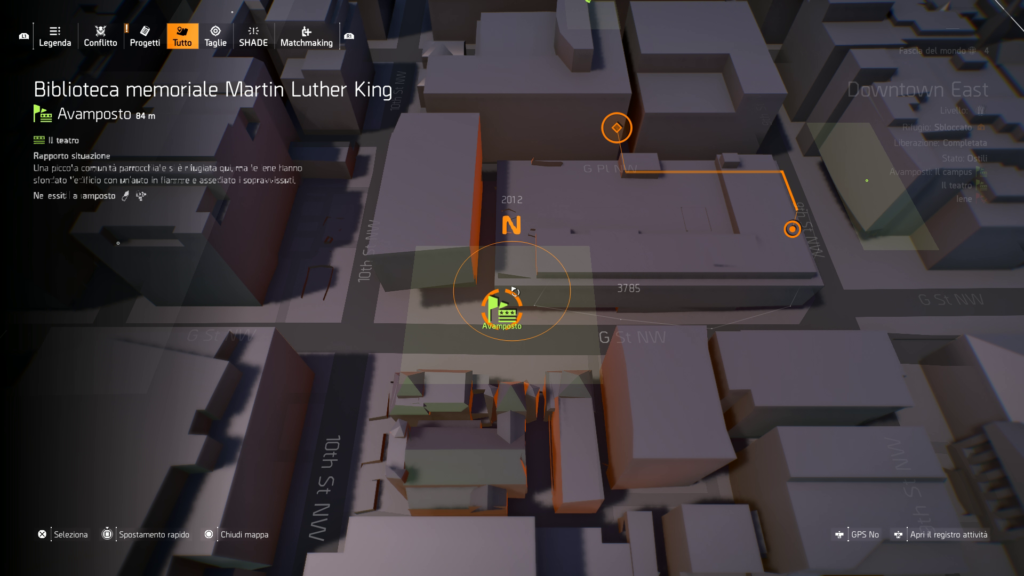
Anzitutto procuriamoci XAMPP dal sito ufficiale. Cliccando sul precedente link ci si troverà di fronte ad una schermata simile:

Selezioniamo la versione più appropriata per il nostro sistema operativo e i nostri scopi; in questa guida io utilizzerò la version indicata con la freccia rossa nell’immagine (XAMPP con PHP 7.3.2, il gruppo a seguire è quello di XAMPP con macchina virtuale).
Una volta scaricato il file selezioniamolo dall’elenco e avviamo l’installazione.

A questo punto clicchiamo sull’installer e autorizziamo l’installazione del programma scaricato da internet.

Adesso si aprirà l’installazione vera e propria e scegliamo di proseguire avanti, come nell’immagine.

Ci verranno chieste una serie di impostazioni da scegliere procedendo avanti. Se non hai particolari esigenze o non sai cosa dovresti scegliere premi tranquillamente next finché non parte l’installazione finale e si giunga alla fine.

A questo punto premiamo su Finish lasciando attiva l’opzione Launch XAMPP. Questo aprirà XAMPP su una schermata simile alla seguente:

Spostiamoci su Manage Servers per avviare i server che ci interessano (ovvero Apache e MySQL).

Per farlo selezioniamo il server MySQL Database e premiamo il tasto Start. Poi selezioniamo il server Apache Web Server e premiamo di nuovo Start.
Una volta avviati correttamente dovremmo vedere al fianco di entrambi un pallino verde. Se così è vuol dire che sono attivi e possiamo procedere oltre.
Adesso torniamo alla schermata precedente e clicchiamo su Open application folder.

Si aprirà la cartella di installazione di XAMPP, qui ci spostiamo su htdocs che è la radice del nostro webserver.
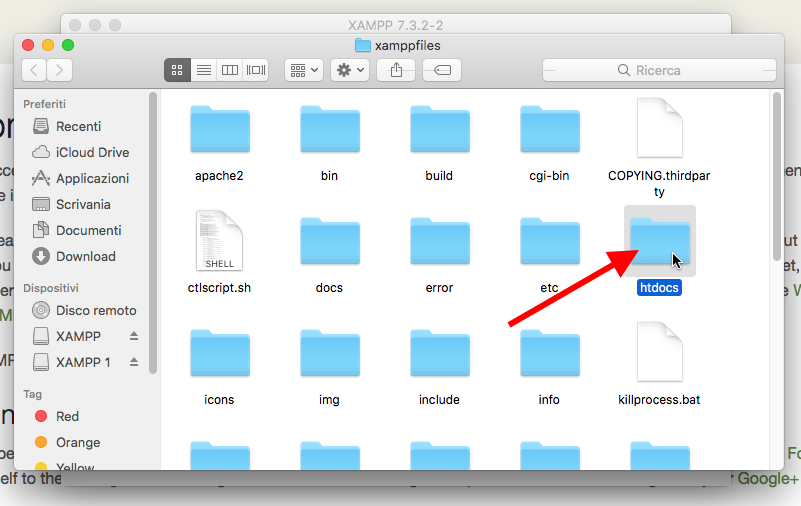
Il contenuto di questa cartella corrisponde all’indirizzo http://localhost oppure http://127.0.0.1
Qui dentro vogliamo creare una cartella dove installeremo WordPress, in modo che sia accessibile all’indirizzo http://localhost/wordpress1
Per farlo clicchiamo col destro e selezioniamo dal menu contestuale Nuova cartella, nominiamo la cartella wordpress1

Adesso lo spazio web è pronto. Dobbiamo solo creare ancora il database. Per farlo andiamo su http://localhost/phpmyadmin. Nella schermata che si apre clicchiamo su Database. Sotto la voce Crea nuovo database inseriamo il nome del database che vogliamo creare, per esempio wordpress1. Il nome del database non deve essere necessariamente uguale al nome della cartella per lo spazio web, li ho messi uguali solo per coerenza logica.

Fatto tutto questo abbiamo preparato spazio web e database per installare il nostro nuovo sito.
Ora dobbiamo procurarci WordPress, quindi andiamo sul sito ufficiale e scarichiamolo dalla sezione download.
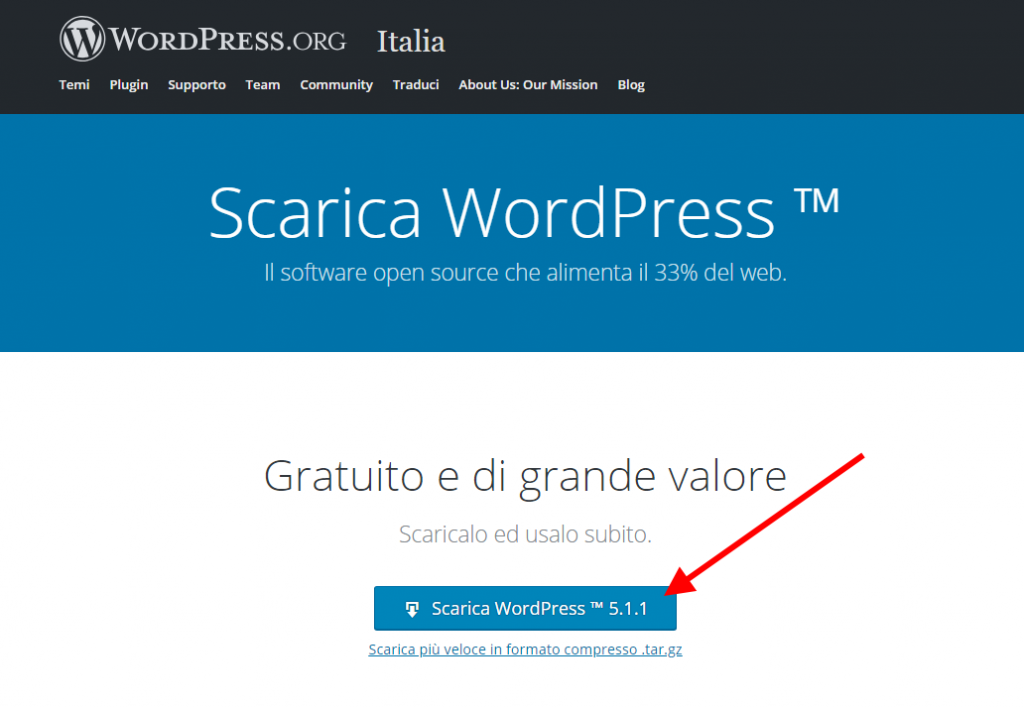
Per l’ultima versione in italiano è anche sufficiente cliccare qui.
Spostiamoci su Safari e andiamo all’indirizzo http://localhost/wordpress1. Se abbiamo fatto tutto correttamente dovremmo vedere qualcosa di simile a questo:

Nel mentre il download di WordPress dovrebbe essere terminato, per cui dovremmo vederlo nell’elenco dei download di Safari nel modo seguente:

Clicchiamo col destro sopra il download e selezioniamo Mostra nel finder.

Dovremmo visualizzare qualcosa di simile. Entriamo nella cartella chiamata wordpress.

Dovremmo trovare un elenco di file come quello mostrato di seguito. Selezioniamo tutti i file e spostiamoli nella cartella wordpress1, che abbiamo creato prima in htdocs. Per farlo è sufficiente affiancare le due finestre e con tutti i file selezionati trascinarli da una posizione all’altra.

Fatto questo, prima di ogni altra cosa, dobbiamo dare i permessi di lettura e scrittura per i file nella cartella di installazione. Perciò dal Finder spostiamoci su Vai > Utility e selezioniamo, dalla finestra che si aprirà, il terminale.
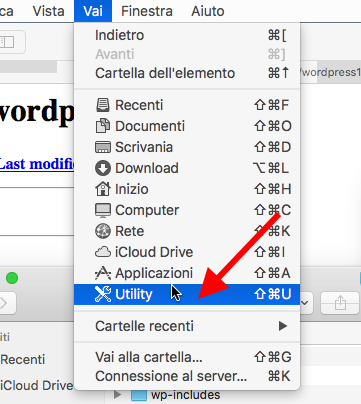
Nel terminale digitiamo: sudo chmod -R 0777
Dopo il 0777 lasciamo uno spazio. Poi affianchiamo la cartella htdocs al terminale e trasciniamo verso il terminale la cartella wordpress1.
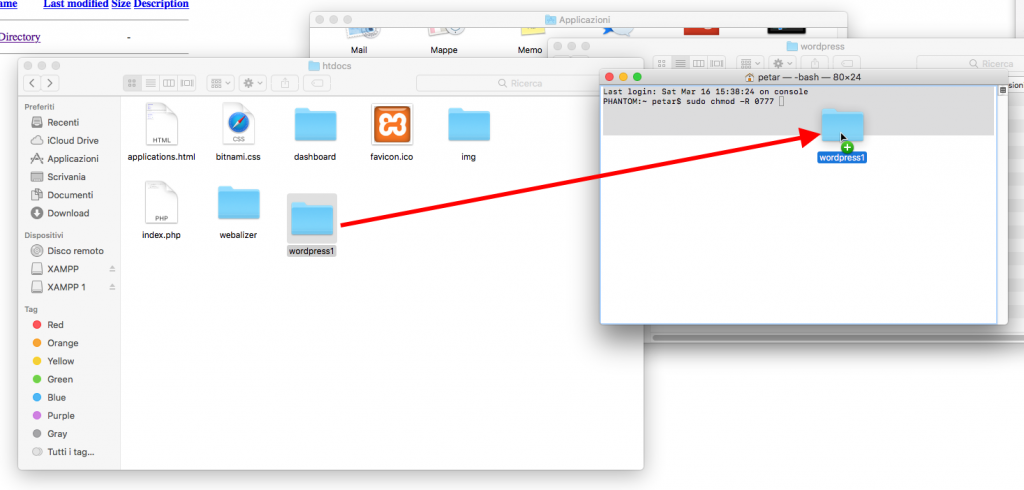
Per essere precisi i permessi 0777 su tutta la cartella consentiranno il massimo accesso a lettura e scrittura per tutti gli utenti e tutti file. Di per se non sarebbe l’ideale, ma siccome stiamo lavorando in locale può andar bene. Ovviamente la situazione andrebbe valutata in base all’uso che si fa del computer in questione.
In ogni caso se tutto è andato bene dovremmo vedere qualcosa come:

Premiamo Invio da tastiera e digitiamo la password. ATTENZIONE! La password non verrà mostrata e sembrerà di digitare a vuoto. Digitiamo la password del nostro utente e premiamo invio, anche se apparentemente non sta succedendo niente.
Aspettiamo un attimo perché la procedura finisca e ricompaia nuovamente il cursore sul terminale. Dopodiché torniamo su Safari e aggiorniamo la pagina http://locahost/wordpress1. Dovremmo trovarci di fronte alla seguente situazione:
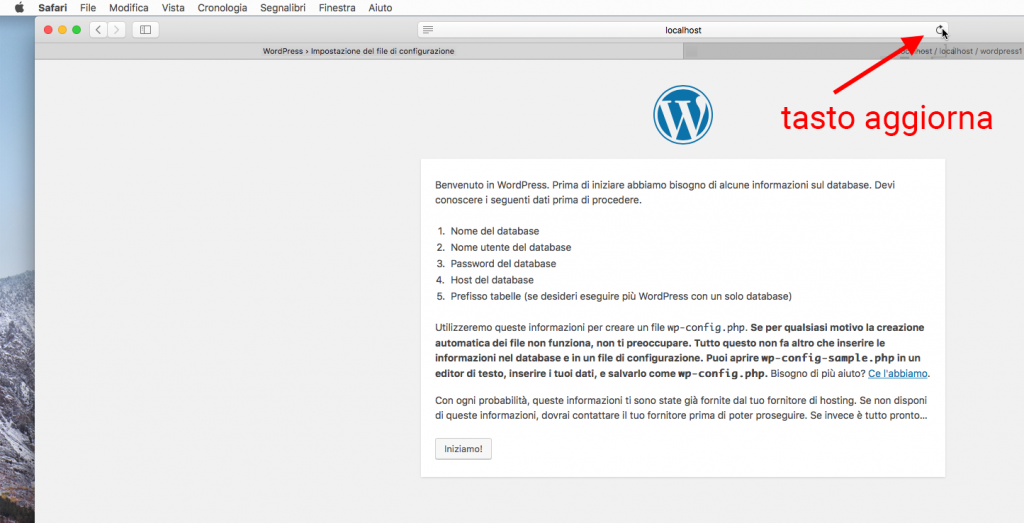
A questo punto possiamo procedere all’installazione di WordPress. Premiamo sul tasto Iniziamo! che compare sotto il testo introduttivo.
Nella schermata che segue inseriamo i dati nella maniera seguente:
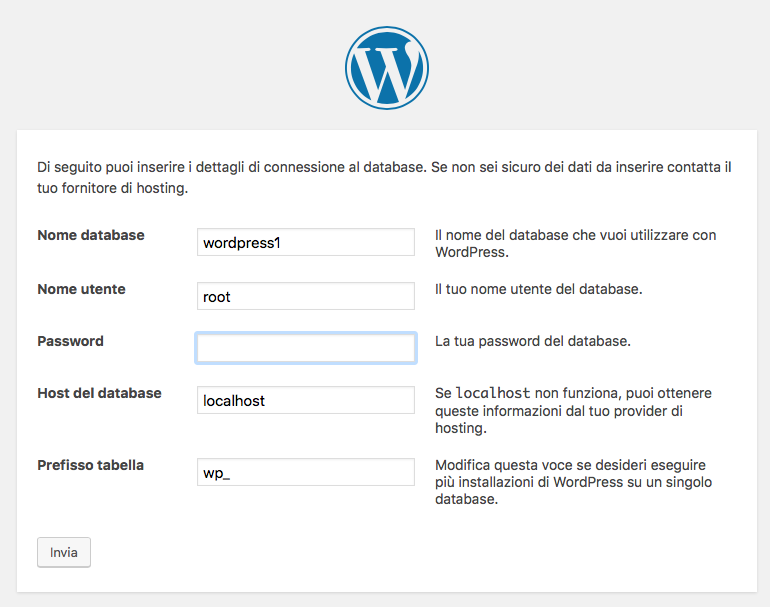
Premiamo su Invia. Se abbiamo messo tutti i campi corretti troveremo la seguente schermata.

Premiamo su Avvia l’installazione. Adesso completiamo la seguente schermata, scegliendo a piacere il nome del sito, il nome dell’utente principale (io ho messo il classico admin), una password (WordPress ce ne suggerirà una abbastanza complessa) e il nostro indirizzo email.

Infine premiamo su Installa WordPress. Se abbiamo eseguito tutto a dovere comparirà la schermata finale di login.

Se installando i plugin o i temi dovesse comparirci una schermata come la seguente:
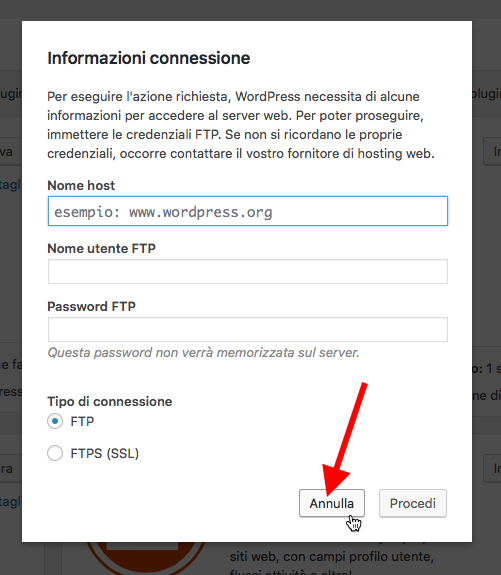
Premiamo sul tasto annulla e dal terminale che abbiamo usato prima per cambiare i permessi digitiamo i seguenti comandi.
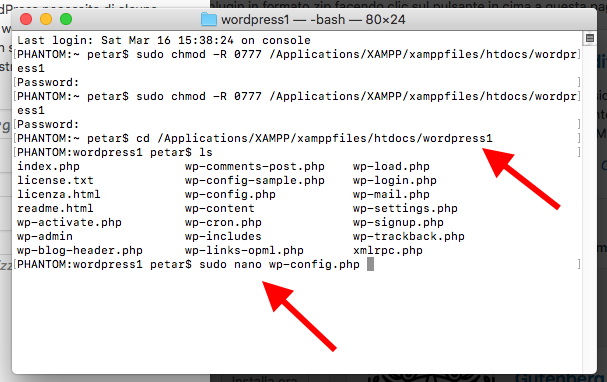
Spostiamoci nella cartella wordpress1 che abbiamo creato con cd wordpress1. Poi digitiamo sudo nano wp-config.php e premiamo il tasto Invio.
Si aprirà l’editor nano sul file wp-config.php.

Subito all’inizio, prima delle impostazioni MySQL, aggiungiamo la seguente riga di codice:
|
|
define('FS_METHOD', 'direct'); |
Premiamo i tasto CTRL+O per salvare. Premiamo Invio per confermare la modifica del file.
Fatto questo possiamo tornare ad installare tranquillamente temi e plugin.